|
|
當一個查詢到達數據庫引擎時,SQL Server執行兩個主要的步驟來產生結果。第一步是查詢編譯,他生成查詢計劃;第二部執行這個查詢計劃。
查詢編譯由三個步驟組成:分析、代數化及查詢優化。然后編譯器把經過優化的查詢計劃保存到過程緩存中。然后執行引擎把該計劃轉換為可執行的形式,然后執行其中的步驟以生成查詢結果。如果今后再執行相同的查詢或存儲過程時,過程緩存已經包含了該計劃,則跳過編譯步驟,直接重用緩存的計劃來執行該查詢或存儲過程。
安裝Northwind數據庫,點選“包括實際的執行計劃”并執行以下查詢:
USE Northwind;
GO
SELECT C.CustomerID, COUNT(O.OrderID) AS NumOrders
FROM dbo.Customers AS C
LEFT OUTER JOIN dbo.Orders AS O
ON C.CustomerID = O.CustomerID
WHERE C.City = 'London'
GROUP BY C.CustomerID
HAVING COUNT(O.OrderID) > 5
ORDER BY NumOrders;
生成結果:
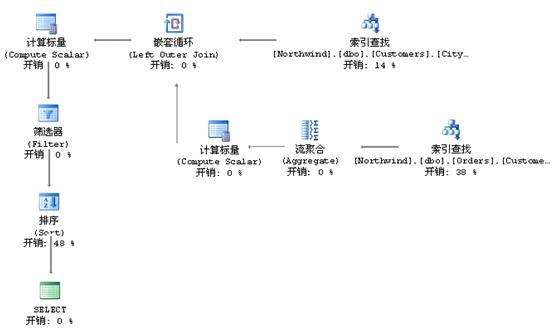
執行計劃流程圖:
文本形式的執行計劃輸出:
|--Sort(ORDER BY:([Expr1004] ASC))
|--Filter(WHERE:([Expr1004]>(5)))
|--Compute Scalar(DEFINE:([Expr1004]=CASE WHEN [Expr1004] IS NULL THEN (0) ELSE [Expr1004] END))
|--Nested Loops(Left Outer Join, OUTER REFERENCES:([C].[CustomerID]))
|--Index Seek(OBJECT:([Northwind].[dbo].[Customers].[City] AS [C]), SEEK:([C].[City]=N'London') ORDERED FORWARD)
|--Compute Scalar(DEFINE:([Expr1004]=CONVERT_IMPLICIT(int,[Expr1009],0)))
|--Stream Aggregate(DEFINE:([Expr1009]=Count(*)))
|--Index Seek(OBJECT:([Northwind].[dbo].[Orders].[CustomersOrders] AS [O]), SEEK:([O].[CustomerID]=[Northwind].[dbo].[Customers].[CustomerID] as [C].[CustomerID]) ORDERED FORWARD)
計劃中的分支是交叉執行的。該示例中SQL Server交替執行嵌套循環的兩個分支。
灰色箭頭表示數據流,箭頭的粗細表示查詢優化器估計通過該連接傳遞的行數。
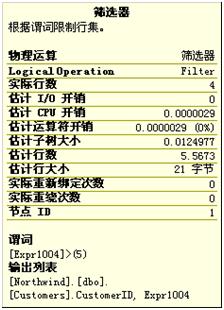
引擎先對Customers表執行索引查找,他將選擇來自London的第一個消費者。可以查看此部操作的詳細信息,如下圖。

可以看到此步的查找謂詞的前綴為:
[Northwind].[dbo].[Customers].[City] = N'London
被選擇的行被傳遞到嵌套循環運算符,嵌套循環則會開始進行內層循環的運算。內層循環由計算標量、流聚合、索引查找組成。

查看一下內層循環的第一步,索引查找的詳細信息,如下圖:

查找謂詞的前綴為:
[Northwind].[dbo].[Orders].CustomerId =
([Northwind].[dbo].[Customers].CustomerID as [C].CustomerID)
我們看到C.CustomerID的值被用于查找Orders表以獲得該CustomerID的所有訂單。也就是說嵌套循環的內側引用了從外側得到的值。
緊接著,查詢會在找到來自London的第一個消費者的所有訂單之后,將這些訂單傳遞給流聚合運算符進行統計。從文本形式的執行計劃輸出上可以很好的理解流聚合在這里做了什么。
|--Stream Aggregate(DEFINE:([Expr1009]=Count(*)))
其實他就是數了一下,有多少個訂單。
然后是計算標量的操作:
|--Compute Scalar(DEFINE:([Expr1004]=CONVERT_IMPLICIT(int,[Expr1009],0)))
其實就是做了一下類型轉換。
然后,內側操作的結果會保存到外側的那行中,說白了就是把London的第一個消費者的訂單數量存在這個消費者對象之中。
那么是不是當所有的嵌套循環執行完成后,形成了一個由(消費者,該消費者的訂單個數)這樣的結構所組成的數組呢?答案是否定的,因為計劃中的分支是交叉執行的。當一個消費者完成了數數的工作,也完成他自己在前4步的操作,進入左上角的計算標量運算符中。
那么然后,由左上角的計算標量來處理這個數據,這個步驟就是做了一下值的檢查:
|--Compute Scalar(DEFINE:([Expr1004]=CASE WHEN [Expr1004] IS NULL THEN (0) ELSE [Expr1004] END))
這里的[Expr1004]在之前已經定義過,還記得吧,首先是求某一個消費者的所有訂單數,然后把值做了類型轉換。這里又增加了一些判斷:如果[Expr1004]是NULL則返回0,否則則執行之前的[Expr1004]。
接著,將結果傳遞給篩選器運算符。
文本形式的執行計劃輸出:
|--Filter(WHERE:([Expr1004]>(5)))
這里很好理解,就是對這條數據進行謂詞操作,如果值不為真,則移除掉該數據。
終于,數據到達了排序運算符。大家應該可以想到,在所有要被排序的行全部就緒之前進行排序是沒有意義的,因此這些行會在排序這一步進行等待,也就是說如果對Customers表的索引查找操作又找到一個來自London的消費者,將重復執行上述過程,直到所有要返回的行到達了排序運算符后,將按正確的順序返回這些行。

文本形式的執行計劃輸出:
|--Sort(ORDER BY:([Expr1004] ASC))
it知識庫:TSQL::(2.1)物理查詢數據流,轉載需保留來源!
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播更多信息之目的,如作者信息標記有誤,請第一時間聯系我們修改或刪除,多謝。



