|
|
1.節(jié)點(node)層次
Document--最頂層的節(jié)點,所有的其他節(jié)點都是附屬于它的。
DocumentType--DTD引用(使用<!DOCTYPE>語法)的對象表現(xiàn)形式,它不能包含子節(jié)點。
DocumentFragment--可以像Document一樣來保存其他節(jié)點。
Element--表示起始標(biāo)簽和結(jié)束標(biāo)簽之間的內(nèi)容,例如<tag></tab>或者<tag/>。這是唯一可以同時包含特性和子節(jié)點的節(jié)點類型。
Attr--代表一對特性名和特性值。這個節(jié)點類型不能包含子節(jié)點。
Text--代表XML文檔中的在起始標(biāo)簽和結(jié)束標(biāo)簽之間,或者CDataSection內(nèi)包含的普通文本。這個節(jié)點類型不能包含子節(jié)點。
CDataSection--<![CDATA[]]>的對象表現(xiàn)形式。這個節(jié)點類型僅能包含文本節(jié)點Text作為子節(jié)點。
Entity--表示在DTD中的一個實體定義,例如<!ENTITY foo"foo">。這個節(jié)點類型不能包含子節(jié)點。
EntityReference--代表一個實體引用,例如"。這個節(jié)點類型不能包含子節(jié)點。
ProcessingInstruction--代表一個PI。這個節(jié)點類型不能包含子節(jié)點。
Comment--代表XML注釋。這個節(jié)點不能包含子節(jié)點。
Notation--代表在DTD中定義的記號。這個很少用到。
Node接口定義了所有節(jié)點類型都包含的特性和方法。
| 特性/方法 | 類型/返回類型 | 說明 |
| nodeName | String | 節(jié)點的名字;根據(jù)節(jié)點的類型而定義 |
| nodeValue | String | 節(jié)點的值;根據(jù)節(jié)點的類型而定義 |
| nodeType | Number | 節(jié)點的類型常量值之一 |
| ownerDocument | Document | 指向這個節(jié)點所屬的文檔 |
| firstChild | Node | 指向在childNodes列表中的第一個節(jié)點 |
| lastChild | Node | 指向在childNodes列表中的最后一個節(jié)點 |
| childNodes | NodeList | 所有子節(jié)點的列表 |
| previousSibling | Node | 指向前一個兄弟節(jié)點;如果這個節(jié)點就是第一個兄弟節(jié)點,那么該值為null |
| nextSibling | Node | 指向后一個兄弟節(jié)點;如果這個節(jié)點就是最后一個兄弟節(jié)點,那么該值為null |
| hasChildNodes() | Boolean | 當(dāng)childNodes包含一個或多個節(jié)點時,返回真 |
| attributes | NamedNodeMap | 包含了代表一個元素的特性的Attr對象;僅用于Element節(jié)點 |
| appendChild(node) | Node | 將node添加到childNodes的末尾 |
| removeChild(node) | Node | 從childNodes中刪除node |
| replaceChild(newnode,oldnode) | Node | 將childNodes中的oldnode替換成newnode |
| insertBefore(newnode,refnode) | Node | 在childNodes中的refnode之前插入newnodd |
除節(jié)點外,DOM還定義了一些助手對象,它們可以和節(jié)點一起使用,但不是DOM文檔必有的部分。
NodeList--節(jié)點數(shù)組,按照數(shù)值進行索引;用來表示和一個元素的子節(jié)點。
NamedNodeMap--同時使用數(shù)值和名字進行索引的節(jié)點表;用于表示元素特性。
2.訪問相關(guān)的節(jié)點
下面的幾節(jié)中考慮下面的HTML頁面
<html>
<head>
<title>DOM Example</title>
</head>
<body>
<p>Hello World!</p>
<p>Isn't this exciting?</p>
<p>You're learning to use the DOM!</p>
</body>
</html>
要訪問<html/>元素(你應(yīng)該明白這是該文件的document元素),你可以使用document的documentElement特性:
var oHtml = document.documentElement;
現(xiàn)在變量oHtml包含一個表示<html/>的HTMLElement對象。如果你想取得<head/>和<body/>元素,下面的可以實現(xiàn):
var oHead = oHtml.firstChild;
var oBody = oHtml.lastChild;
也可以使用childNodes特性來完成同樣的工作。只需把它當(dāng)成普通的Javascript array,使用方括號標(biāo)記:
var oHead = oHtml.childNodes[0];
var oBody = oHtml.childNodes[1];
注意方括號標(biāo)記其實是NodeList在Javascript中的簡便實現(xiàn)。實際上正式的從childNodes列表中獲取子節(jié)點的方法是使用item()方法:
var oHead = oHtml.childNodes.item(0);
var oBody = oHtml.childNodes.item(1);
HTML DOM頁定義了document.body作為指向<body/>元素的指針。
var oBody = ducument.body;
有了oHtml,oHead和oBody這三個變量,就可以嘗試確定它們之間的關(guān)系:
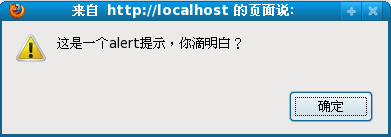
alert(oHead.parentNode==oHtml);
alert(oBody.parentNode==oHtml);
alert(oBody.previousSibling==oHead);
alert(bHead.nextSibling==oBody);
alert(oHead.ownerDocument==document);
以上均outputs "true"。
3.處理特性
正如前面所提到的,即便Node接口已具有attributes方法,且已被所有類型的節(jié)點繼承,然而,只有
Element節(jié)點才能有特性。Element節(jié)點的attributes屬性其實是NameNodeMap,它提供一些用于訪問和處理其內(nèi)容的方法:
getNamedItem(name)--返回nodename屬性值等于name的節(jié)點;
removeNamedItem(name)--刪除nodename屬性值等于name的節(jié)點;
setNamedItem(node)--將node添加到列表中,按其nodeName屬性進行索引;
item(pos)--像NodeList一樣,返回在位置pos的節(jié)點;
注:請記住這些方法都是返回一個Attr節(jié)點,而非特性值。
NamedNodeMap對象也有一個length屬性來指示它所包含的節(jié)點的數(shù)量。
當(dāng)NamedNodeMap用于表示特性時,其中每個節(jié)點都是Attr節(jié)點,這的nodeName屬性被設(shè)置為特性名稱,而nodeValue屬性被設(shè)置為特性的值。例如,假設(shè)有這樣一個元素:
<p style="color:red" id="p1">Hello world!</p>
同時,假設(shè)變量oP包含指向這個元素的一個引用。于是可以這樣訪問id特性的值:
var sId = oP.attributes.getNamedItem("id").nodeValue;
當(dāng)然,還可以用數(shù)值方式訪問id特性,但這樣稍微有些不直觀:
var sId = oP.attributes.item(1).nodeValue;
還可以通過給nodeValue屬性賦新值來改變id特性:
oP.attributes.getNamedItem("id").nodeValue="newId";
Attr節(jié)點也有一個完全等同于(同時也完全同步于)nodeValue屬性的value屬性,并且有name屬性和nodeName屬性保持同步。我們可以隨意使用這些屬性來修改或變更特性。
因為這個方法有些累贅,DOM又定義了三個元素方法來幫助訪問特性:
getAttribute(name)--等于attributes.getNamedItem(name).value;
setAttribute(name,newvalue)--等于attribute.getNamedItem(name).value=newvalue;
removeAttribute(name)--等于attribute.removeNamedItem(name)。
4.訪問指定節(jié)點
(1)getElementsByTagName()
核心(XML) DOM定義了getElementsByTagName()方法,用來返回一個包含所有的tagName(標(biāo)簽名)特性等于某個指定值的元素的NodeList。在Element對象中,tagName特性總是等于小于號之后緊跟隨的名稱--例如,<img />的tagName是"img"。下一行代碼返回文檔中所有<img />元素的列表:
var oImgs = document.getElementsByTagName("img");
把所有圖形都存于oImgs后,只需使用方括號或者Item()方法(getElementsByTagName()返回一個和childNodes一樣的NodeList),就可以像訪問子節(jié)點那樣逐個訪問這些節(jié)點了:
alert(oImgs[0].tagName); //outputs "IMG"
假如只想獲取在某個頁面第一個段落的所有圖像,可以通過對第一個段落元素調(diào)用getElementsByTagName()來完成,像這樣:
var oPs = document.getElementByTagName("p");
var oImgsInp = oPs[0].getElementByTagName("img");
可以使用一個星號的方法來獲取document中的所有元素:
var oAllElements = document.getElementsByTagName("*");
當(dāng)參數(shù)是一個星號的時候,IE6.0并不返回所有的元素。必須使用document.all來替代它。
(2)getElementsByName()
HTML DOM 定義了getElementsByName(),這用來獲取所有name特性等于指定值的元素的。
(3)getElementById()
這是HTML DOM定義的第二種方法,它將返回id特性等于指定值的元素。在HTML中,id特性是唯一的--這意味著沒有兩個元素可以共享同一個id。毫無疑問這是從文檔樹中獲取單個指定元素最快的方法。
注:如果給定的ID匹配某個元素的name特性,IE6.0還會返回這個元素。這是一個bug,也是必須非常小心的一個問題。
JavaScript技術(shù):比較詳細(xì)的javascript DOM 學(xué)習(xí)筆記第1/2頁,轉(zhuǎn)載需保留來源!
鄭重聲明:本文版權(quán)歸原作者所有,轉(zhuǎn)載文章僅為傳播更多信息之目的,如作者信息標(biāo)記有誤,請第一時間聯(lián)系我們修改或刪除,多謝。