|
|
1. 技術(shù)背景—FaceBook頁面加載技術(shù)
試想這樣一個場景,一個經(jīng)常訪問的網(wǎng)站,每次打開它的頁面都要要花費6秒;同時另外一個網(wǎng)站提供了相似的服務(wù),但響應(yīng)時間只需3 秒,那么你會如何選擇呢?數(shù)據(jù)表明,如果用戶打開一個網(wǎng)站,等待3~4 秒還沒有任何反應(yīng),他們會變得急躁,焦慮,抱怨,甚至關(guān)閉網(wǎng)頁并且不再訪問,這是非常糟糕的情況。所以,網(wǎng)頁加載的速度十分重要,尤其對于擁有遍布全球的5億用戶的Facebook(全球最大的社交服務(wù)網(wǎng)站)這樣的大型網(wǎng)站,有著大量并發(fā)請求、海量數(shù)據(jù)等客觀情況,速度就成了必須攻克的難題之一。
2010年初的時候,F(xiàn)acebook 的前端性能研究小組開始了他們的優(yōu)化項目,經(jīng)過了六個月的努力,成功的將個人空間主頁面加載耗時由原來的5 秒減少為現(xiàn)在的2.5 秒。這是一個非常了不起的成就,也給用戶來帶來了很好的體驗。在優(yōu)化項目中,工程師提出了一種新的頁面加載技術(shù),稱之為Bigpipe。目前淘寶和Facebook面臨的問題非常相似:海量數(shù)據(jù)和頁面過大,如果可以在詳情頁、列表頁中使用bigpipe,或者在webx中集成bigpipe,將會帶來明顯的頁面加載速度提升。
2. 相關(guān)介紹
2.1 網(wǎng)站前端優(yōu)化的重要性
《高性能網(wǎng)站建設(shè)指南》一書中指出,只有10%~20%的最終用戶響應(yīng)時間是花費在從Web服務(wù)器獲取HTML文檔并傳送到瀏覽器中的。如果希望能夠有效地減少頁面的響應(yīng)時間,就必須關(guān)注剩余的80%~90%的最終用戶體驗。做個比較,如果對后臺業(yè)務(wù)邏輯進行優(yōu)化,效率提高了50%,但最終的頁面響應(yīng)時間只減少了5%~10%,因為它所占的比重較少。如果對前端進行性能優(yōu)化,效率提升50%,則會使最終頁面響應(yīng)時間減少40%~45%。這是多么可觀的數(shù)字!另外,前端的性能優(yōu)化一般比業(yè)務(wù)邏輯的優(yōu)化更加容易。所以,前端優(yōu)化投入小,見效快,性價比極高,需要投入更多的關(guān)注。
2.2 BigPipe與AJAX
Web2.0的重要特征是網(wǎng)頁顯示大量動態(tài)內(nèi)容,即web2.0注重網(wǎng)頁與用戶的交互。其核心技術(shù)是AJAX,如今所有主流網(wǎng)站都或多或少使用AJAX。與AJAX類似,BigPipe實現(xiàn)了分塊兒的概念,使頁面能夠分步輸出,即每次輸出一部分網(wǎng)頁內(nèi)容。接下來討論BigPipe與AJAX的區(qū)別。
簡單的說,BigPipe比AJAX有三個好處:
1. AJAX 的核心是XMLHttpRequest,客戶端需要異步的向服務(wù)器端發(fā)送請求,然后將傳送過來的內(nèi)容動態(tài)添加到網(wǎng)頁上。如此實現(xiàn)存在一些缺陷,即發(fā)送往返請求需要耗費時間,而BigPipe技術(shù)使瀏覽器并不需要發(fā)送XMLHttpRequest請求,這樣就節(jié)省時間損耗。
2. 使用AJAX時,瀏覽器和服務(wù)器的工作順序執(zhí)行。服務(wù)器必須等待瀏覽器的請求,這樣就會造成服務(wù)器的空閑。瀏覽器工作時,服務(wù)器在等待,而服務(wù)器工作時,瀏覽器在等待,這也是一種性能的浪費。使用BigPipe,瀏覽器和服務(wù)器可以并行同時工作,服務(wù)器不需要等待瀏覽器的請求,而是一直處于加載頁面內(nèi)容的工作階段,這就會使效率得到更大的提高。
3. 減少瀏覽器發(fā)送到請求。對一個5億用戶的網(wǎng)站來說,減少了使用AJAX額外帶來的請求,會減少服務(wù)器的負(fù)載,同樣會帶來很大的性能提升。
基于以上三點,F(xiàn)acebook 在進行頁面優(yōu)化時采用了BigPipe技術(shù)。目前淘寶主搜索結(jié)果頁中,需要加載類目,相關(guān)搜索,寶貝列表,廣告等內(nèi)容,前端這里使用php的curl的批處理來并發(fā)的訪問引擎獲取相應(yīng)的數(shù)據(jù),并進行分步輸出。這種模式還是與bigpipe有些不同,這點后面會講到。一般來講,在頁面比較大,而且比較復(fù)雜,樣式表和腳本比較多的情況下,使用BigPipe來優(yōu)化輸出頁面是比較合適的。另外非常重要的一點,BigPipe并不改變?yōu)g覽器的結(jié)構(gòu)與網(wǎng)絡(luò)協(xié)議,僅使用JS就可以實現(xiàn),用戶不需要做任何的設(shè)置,就會看到明顯的訪問時間縮短。
3. 目前的問題
接下來討論現(xiàn)有的瓶頸。面對網(wǎng)頁越來越大的情況,尤其是大量的css文件和js文件需要加載,傳統(tǒng)的頁面加載模型很難滿足這樣的需求,直接結(jié)果就是頁面加載速度變慢,這絕不是我們希望看到的。目前的技術(shù)實現(xiàn)中,用戶提出頁面訪問請求后,頁面的完整加載流程如下:
1. 用戶訪問網(wǎng)頁,瀏覽器發(fā)送一個HTTP請求到網(wǎng)絡(luò)服務(wù)器。
2. 服務(wù)器解析這個請求,然后從存儲層取數(shù)據(jù),接著生成一個html文件內(nèi)容,并在一個HTTP Response中把它傳送給客戶端。
3. HTTP response在網(wǎng)絡(luò)中傳輸。
4. 瀏覽器解析這個Response ,創(chuàng)建一個DOM樹,然后下載所需的CSS和JS文件。
5. 下載完CSS 文件后,瀏覽器解析他們并且應(yīng)用在相應(yīng)的內(nèi)容上。
6. 下載完JS 后,瀏覽器解析和執(zhí)行他們
 圖1
圖1
完整流程見圖1。圖中左側(cè)表示服務(wù)器,右側(cè)表示瀏覽器。瀏覽器先發(fā)送請求,然后服務(wù)器進行查找數(shù)據(jù),生成頁面,返回html代碼,最后瀏覽器進行渲染頁面。這種模式有非常明顯的缺陷:流程中的操作有著嚴(yán)格的順序,如果前面的一個操作沒有執(zhí)行結(jié)束,后面的操作就不能執(zhí)行,即操作之間是不能重疊。這樣就造成性能的瓶頸:服務(wù)器生成一個頁面的內(nèi)容時,瀏覽器是空閑的,顯示空白內(nèi)容;而當(dāng)瀏覽器加載渲染頁面內(nèi)容時,服務(wù)器又是空閑的,時間與性能的浪費由此產(chǎn)生。
 圖2
圖2
考慮圖2中現(xiàn)有的服務(wù)模型,橫軸表示花費的時間。黃色表示在服務(wù)器的生成頁面內(nèi)容的時間,白色表示網(wǎng)絡(luò)傳輸時間,藍(lán)色表示在瀏覽器渲染頁面的時間。可以看出,現(xiàn)有的模式造成很大的時間浪費。考慮圖3中的情況,圖中綠色表示服務(wù)器從春儲層取查數(shù)據(jù)花費的時間,在海量數(shù)據(jù)下,當(dāng)執(zhí)行一條很費時的查詢語句時(如下圖右側(cè)),服務(wù)器就就阻塞在那里沒有其他操作,而瀏覽器更是得不到任何反饋。這會造成非常不友好的用戶體驗,用戶不知道什么原因使他們等待很長時間。
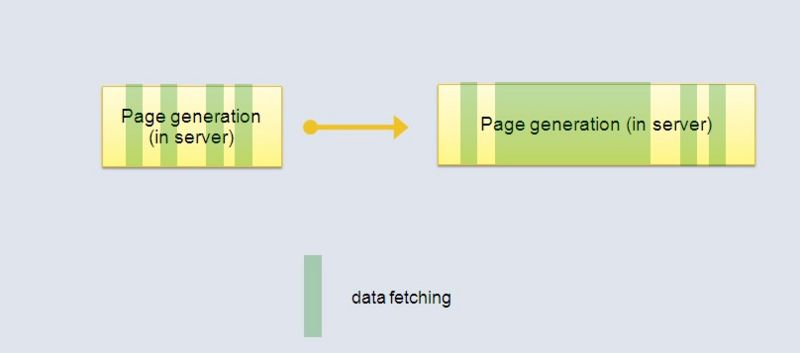 圖3
圖3
4. BigPipe思想與原理
面對上述問題,我們看下BigPipe的解決辦法。BigPipe提出分塊的概念,即根據(jù)頁面內(nèi)容位置的不同,將整個頁面分成不同的塊兒—稱為pagelet。該技術(shù)的設(shè)計者Changhao Jiang是研究電子電路的博士,可能從微機上得到了啟發(fā),將眾多pagelet加載的不同階段像流水線一樣在瀏覽器和服務(wù)器上執(zhí)行,這樣就做到了瀏覽器和服務(wù)器的并行化,從而達(dá)到重疊服務(wù)器端運行時間和瀏覽器端運行時間的目的。使用BigPipe不僅可以節(jié)省時間,使加載的時間縮短,而且可以同過pagelet的分步輸出,使一部分的頁面內(nèi)容更快的輸出,從而獲得更好的用戶體驗。BigPipe中,用戶提出頁面訪問請求后,頁面的完整加載流程如下:
1. Request parsing:服務(wù)器解析和檢查http request
2. Datafetching:服務(wù)器從存儲層獲取數(shù)據(jù)
3. Markup generation:服務(wù)器生成html 標(biāo)記
4. NETwork transport : 網(wǎng)絡(luò)傳輸response
5. CSS downloading:瀏覽器下載CSS
6. DOM tree construction and CSS styling:瀏覽器生成DOM 樹,并且使用CSS
7. JavaScript downloading: 瀏覽器下載頁面引用的JS文件
8. JavaScript execution: 瀏覽器執(zhí)行頁面JS代碼
這個8 個流程幾乎與上文中提到現(xiàn)有的模式?jīng)]有區(qū)別,但這整個流程只是一個pagelet 的完整流程,而多個pagelet 的不同操作階段就可以像流水線一樣進行執(zhí)行了。
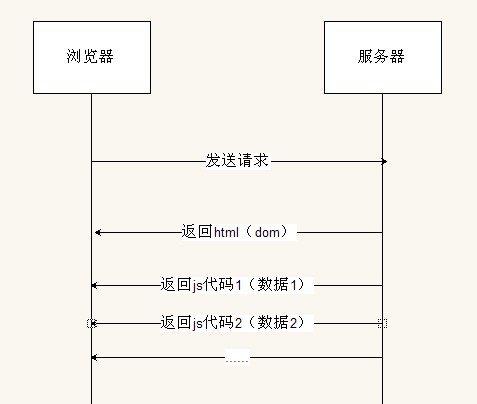 圖4
圖4
圖4 中,可以看出BigPipe對原有的模式進行的改進。瀏覽器發(fā)送訪問請求,然后瀏覽器分步返回不同的pagelet的內(nèi)容,具體實現(xiàn)將在后面介紹。考慮圖5中的改進,BigPipe 打破了原有的順序執(zhí)行,將頁面分成不同的pagelet ,如此一來,所有的pagelet 的執(zhí)行時間累加起來還是原有的時間。但是, 通過疊加不同pagelet 的不同階段的執(zhí)行時間,使總的運行時間大大減少,這就是Bigpipe減少頁面加載時間的秘密。
FaceBook的頁面被分成了很多不同的pagelets,如圖:
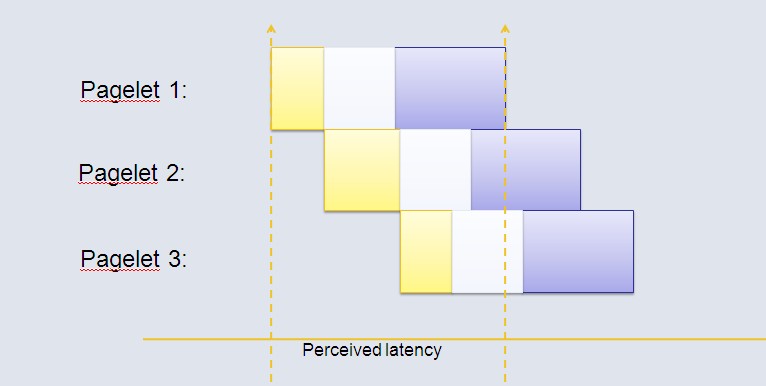 圖5
圖5
5. BigPipe實現(xiàn)原理
了解了BigPipe 的核心思想后,我們討論它的實現(xiàn)原理。當(dāng)瀏覽器訪問服務(wù)器時,服務(wù)器接受請求并對其進行檢查。如果請求有效,服務(wù)器端不做任何的查詢,而是立刻返回一個http response給瀏覽器,內(nèi)容是一段html代碼,包括html<head> 標(biāo)簽和<body> 標(biāo)簽的一部分。<head>標(biāo)簽包括BigPipe的js文件和css文件,這個js文件用來解析后面接收的http response,因為后面?zhèn)鬏數(shù)膬?nèi)容都為js腳本。未封閉的<body>標(biāo)簽中,是顯示頁面的邏輯結(jié)構(gòu)和pagelet 的占位符的模板,例如:
<body>
<div></div>
<div></div>
<div></div>
<div>
<div>
<div id=”hotnews”></div>
<div id=”societynews”></div>
<div id=”financialnews”></div>
<div id=”ITnews”></div>
<div id=”sportsnews”></div>
</div>
<div></div>
</div>
<div></div>
it知識庫:BigPipe學(xué)習(xí)研究,轉(zhuǎn)載需保留來源!
鄭重聲明:本文版權(quán)歸原作者所有,轉(zhuǎn)載文章僅為傳播更多信息之目的,如作者信息標(biāo)記有誤,請第一時間聯(lián)系我們修改或刪除,多謝。



