|
|
目錄
一、介紹
二、渲染引擎
三、解析與DOM樹構建
四、渲染樹構建
五、布局
六、繪制
七、動態變化
八、渲染引擎的線程
九、CSS2可視模型
英文原文:How Browsers Work: Behind the Scenes of Modern Web Browsers
瀏覽器可以被認為是使用最廣泛的軟件,本文將介紹瀏覽器的工作原理,我們將看到,從你在地址欄輸入google.com到你看到google主頁過程中都發生了什么。
將討論的瀏覽器
今天,有五種主流瀏覽器——IE、Firefox、Safari、Chrome及Opera。
本文將基于一些開源瀏覽器的例子——Firefox、Chrome及Safari,Safari是部分開源的。
根據W3C(World Wide Web Consortium萬維網聯盟)的瀏覽器統計數據,當前(2011年5月),Firefox、Safari及Chrome的市場占有率綜合已接近60%。(原文為2009年10月,數據沒有太大變化)因此,可以說開源瀏覽器已經占據了瀏覽器市場的半壁江山。
瀏覽器的主要功能
瀏覽器的主要功能是將用戶選擇的web資源呈現出來,它需要從服務器請求資源,并將其顯示在瀏覽器窗口中,資源的格式通常是HTML,也包括PDF、image及其他格式。用戶用URI(Uniform Resource Identifier統一資源標識符)來指定所請求資源的位置,在網絡一章有更多討論。
HTML和CSS規范中規定了瀏覽器解釋html文檔的方式,由W3C組織對這些規范進行維護,W3C是負責制定web標準的組織。
HTML規范的最新版本是HTML4(http://www.w3.org/TR/html401/),HTML5還在制定中(譯注:兩年前),最新的CSS規范版本是2(http://www.w3.org/TR/CSS2),CSS3也還正在制定中(譯注:同樣兩年前)。
這些年來,瀏覽器廠商紛紛開發自己的擴展,對規范的遵循并不完善,這為web開發者帶來了嚴重的兼容性問題。
但是,瀏覽器的用戶界面則差不多,常見的用戶界面元素包括:
- 用來輸入URI的地址欄
- 前進、后退按鈕
- 書簽選項
- 用于刷新及暫停當前加載文檔的刷新、暫停按鈕
- 用于到達主頁的主頁按鈕
奇怪的是,并沒有哪個正式公布的規范對用戶界面做出規定,這些是多年來各瀏覽器廠商之間相互模仿和不斷改進的結果。
HTML5并沒有規定瀏覽器必須具有的UI元素,但列出了一些常用元素,包括地址欄、狀態欄及工具欄。還有一些瀏覽器有自己專有的功能,比如Firefox的下載管理。更多相關內容將在后面討論用戶界面時介紹。
瀏覽器的主要構成(High Level Structure)
瀏覽器的主要組件包括:
1. 用戶界面 - 包括地址欄、后退/前進按鈕、書簽目錄等,也就是你所看到的除了用來顯示你所請求頁面的主窗口之外的其他部分。
2. 瀏覽器引擎 - 用來查詢及操作渲染引擎的接口。
3. 渲染引擎 - 用來顯示請求的內容,例如,如果請求內容為html,它負責解析html及css,并將解析后的結果顯示出來。
4. 網絡 - 用來完成網絡調用,例如http請求,它具有平臺無關的接口,可以在不同平臺上工作。
5. UI后端 - 用來繪制類似組合選擇框及對話框等基本組件,具有不特定于某個平臺的通用接口,底層使用操作系統的用戶接口。
6. JS解釋器 - 用來解釋執行JS代碼。
7. 數據存儲 - 屬于持久層,瀏覽器需要在硬盤中保存類似cookie的各種數據,HTML5定義了web database技術,這是一種輕量級完整的客戶端存儲技術
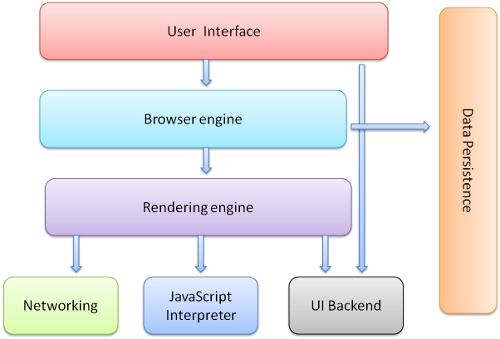
圖1:瀏覽器主要組件
需要注意的是,不同于大部分瀏覽器,Chrome為每個Tab分配了各自的渲染引擎實例,每個Tab就是一個獨立的進程。
對于構成瀏覽器的這些組件,后面會逐一詳細討論。
二、渲染引擎(The rendering engine)
渲染引擎的職責就是渲染,即在瀏覽器窗口中顯示所請求的內容。
默認情況下,渲染引擎可以顯示html、xml文檔及圖片,它也可以借助插件(一種瀏覽器擴展)顯示其他類型數據,例如使用PDF閱讀器插件,可以顯示PDF格式,將由專門一章講解插件及擴展,這里只討論渲染引擎最主要的用途——顯示應用了CSS之后的html及圖片。
渲染引擎簡介
本文所討論的瀏覽器——Firefox、Chrome和Safari是基于兩種渲染引擎構建的,Firefox使用Geoko——Mozilla自主研發的渲染引擎,Safari和Chrome都使用webkit。
Webkit是一款開源渲染引擎,它本來是為Linux平臺研發的,后來由Apple移植到Mac及Windows上,相關內容請參考http://webkit.org。
渲染主流程(The main flow)
渲染引擎首先通過網絡獲得所請求文檔的內容,通常以8K分塊的方式完成。
下面是渲染引擎在取得內容之后的基本流程:
解析html以構建dom樹 -> 構建render樹 -> 布局render樹 -> 繪制render樹

圖2:渲染引擎基本流程
渲染引擎開始解析html,并將標簽轉化為內容樹中的dom節點。接著,它解析外部CSS文件及style標簽中的樣式信息。這些樣式信息以及html中的可見性指令將被用來構建另一棵樹——render樹。
Render樹由一些包含有顏色和大小等屬性的矩形組成,它們將被按照正確的順序顯示到屏幕上。
Render樹構建好了之后,將會執行布局過程,它將確定每個節點在屏幕上的確切坐標。再下一步就是繪制,即遍歷render樹,并使用UI后端層繪制每個節點。
值得注意的是,這個過程是逐步完成的,為了更好的用戶體驗,渲染引擎將會盡可能早的將內容呈現到屏幕上,并不會等到所有的html都解析完成之后再去構建和布局render樹。它是解析完一部分內容就顯示一部分內容,同時,可能還在通過網絡下載其余內容。
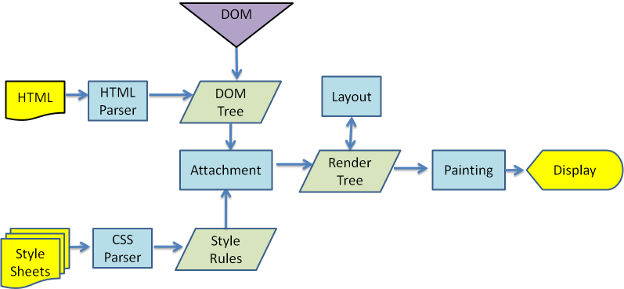
圖3:webkit主流程
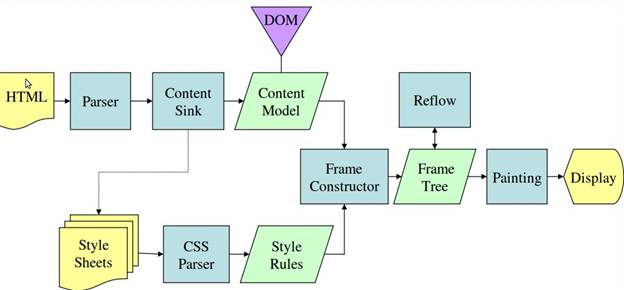
圖4:Mozilla的Geoko渲染引擎主流程
從圖3和4中可以看出,盡管webkit和Gecko使用的術語稍有不同,他們的主要流程基本相同。Gecko稱可見的格式化元素組成的樹為frame樹,每個元素都是一個frame,webkit則使用render樹這個名詞來命名由渲染對象組成的樹。Webkit中元素的定位稱為布局,而Gecko中稱為回流。Webkit稱利用dom節點及樣式信息去構建render樹的過程為attachment,Gecko在html和dom樹之間附加了一層,這層稱為內容接收器,相當制造dom元素的工廠。下面將討論流程中的各個階段。
三、解析與DOM樹構建(Parsing and DOM tree construction)
解析(Parsing-general)
既然解析是渲染引擎中一個非常重要的過程,我們將稍微深入的研究它。首先簡要介紹一下解析。
解析一個文檔即將其轉換為具有一定意義的結構——編碼可以理解和使用的東西。解析的結果通常是表達文檔結構的節點樹,稱為解析樹或語法樹。
例如,解析“2+3-1”這個表達式,可能返回這樣一棵樹。
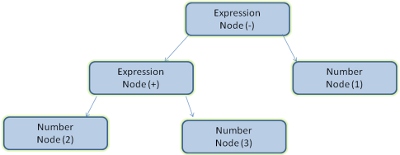
圖5:數學表達式樹節點
文法(Grammars)
解析基于文檔依據的語法規則——文檔的語言或格式。每種可被解析的格式必須具有由詞匯及語法規則組成的特定的文法,稱為上下文無關文法。人類語言不具有這一特性,因此不能被一般的解析技術所解析。
解析器-詞法分析器(Parser-Lexer combination)
解析可以分為兩個子過程——語法分析及詞法分析
詞法分析就是將輸入分解為符號,符號是語言的詞匯表——基本有效單元的集合。對于人類語言來說,它相當于我們字典中出現的所有單詞。
語法分析指對語言應用語法規則。
解析器一般將工作分配給兩個組件——詞法分析器(有時也叫分詞器)負責將輸入分解為合法的符號,解析器則根據語言的語法規則分析文檔結構,從而構建解析樹,詞法分析器知道怎么跳過空白和換行之類的無關字符。
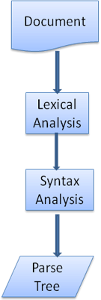
圖6:從源文檔到解析樹
解析過程是迭代的,解析器從詞法分析器處取到一個新的符號,并試著用這個符號匹配一條語法規則,如果匹配了一條規則,這個符號對應的節點將被添加到解析樹上,然后解析器請求另一個符號。如果沒有匹配到規則,解析器將在內部保存該符號,并從詞法分析器取下一個符號,直到所有內部保存的符號能夠匹配一項語法規則。如果最終沒有找到匹配的規則,解析器將拋出一個異常,這意味著文檔無效或是包含語法錯誤。
轉換(Translation)
很多時候,解析樹并不是最終結果。解析一般在轉換中使用——將輸入文檔轉換為另一種格式。編譯就是個例子,編譯器在將一段源碼編譯為機器碼的時候,先將源碼解析為解析樹,然后將該樹轉換為一個機器碼文檔。
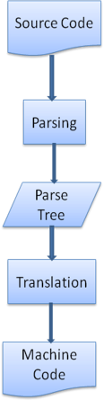
圖7:編譯流程
解析實例Parsing example
圖5中,我們從一個數學表達式構建了一個解析樹,這里定義一個簡單的數學語言來看下解析過程。
詞匯表:我們的語言包括整數、加號及減號。
語法:
1. 該語言的語法基本單元包括表達式、term及操作符
2. 該語言可以包括多個表達式
3. 一個表達式定義為兩個term通過一個操作符連接
4. 操作符可以是加號或減號
5. term可以是一個整數或一個表達式
現在來分析一下“2+3-1”這個輸入
第一個匹配規則的子字符串是“2”,根據規則5,它是一個term,第二個匹配的是“2+3”,它符合第2條規則——一個操作符連接兩個term,下一次匹配發生在輸入的結束處。“2+3-1”是一個表達式,因為我們已經知道“2+3”是一個term,所以我們有了一個term緊跟著一個操作符及另一個term。“2++”將不會匹配任何規則,因此是一個無效輸入。
詞匯表及語法的定義
詞匯表通常利用正則表達式來定義。
例如上面的語言可以定義為:
INTEGER:0|[1-9][0-9]*
PLUS:+
MINUS:-
正如看到的,這里用正則表達式定義整數。
語法通常用BNF格式定義,我們的語言可以定義為:
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression
如果一個語言的文法是上下文無關的,則它可以用正則解析器來解析。對上下文無關文法的一個直觀的定義是,該文法可以用BNF來完整的表達。可查看http://en.wikipedia.org/wiki/Context-free_grammar。
解析器類型(Types of parsers)
有兩種基本的解析器——自頂向下解析及自底向上解析。比較直觀的解釋是,自頂向下解析,查看語法的最高層結構并試著匹配其中一個;自底向上解析則從輸入開始,逐步將其轉換為語法規則,從底層規則開始直到匹配高層規則。
來看一下這兩種解析器如何解析上面的例子:
自頂向下解析器從最高層規則開始——它先識別出“2+3“,將其視為一個表達式,然后識別出”2+3-1“為一個表達式(識別表達式的過程中匹配了其他規則,但出發點是最高層規則)。
自底向上解析會掃描輸入直到匹配了一條規則,然后用該規則取代匹配的輸入,直到解析完所有輸入。部分匹配的表達式被放置在解析堆棧中。
Stack | Input |
2 + 3 – 1 | |
term | + 3 - 1 |
term operation | 3 – 1 |
expression | - 1 |
expression operation | 1 |
expression |
自底向上解析器稱為shift reduce解析器,因為輸入向右移動(想象一個指針首先指向輸入開始處,并向右移動),并逐漸簡化為語法規則。
自動化解析(Generating parsers automatically)
解析器生成器這個工具可以自動生成解析器,只需要指定語言的文法——詞匯表及語法規則,它就可以生成一個解析器。創建一個解析器需要對解析有深入的理解,而且手動的創建一個由較好性能的解析器并不容易,所以解析生成器很有用。Webkit使用兩個知名的解析生成器——用于創建語法分析器的Flex及創建解析器的Bison(你可能接觸過Lex和Yacc)。Flex的輸入是一個包含了符號定義的正則表達式,Bison的輸入是用BNF格式表示的語法規則。
HTML解析器(HTML Parser)
HTML解析器的工作是將html標識解析為解析樹。
HTML文法定義(The HTML grammar definition)
W3C組織制定規范定義了HTML的詞匯表和語法。
非上下文無關文法(Not a context free grammar)
正如在解析簡介中提到的,上下文無關文法的語法可以用類似BNF的格式來定義。
不幸的是,所有的傳統解析方式都不適用于html(當然我提出它們并不只是因為好玩,它們將用來解析css和js),html不能簡單的用解析所需的上下文無關文法來定義。
Html有一個正式的格式定義——DTD(Document Type Definition文檔類型定義)——但它并不是上下文無關文法,html更接近于xml,現在有很多可用的xml解析器,html有個xml的變體——xhtml,它們間的不同在于,html更寬容,它允許忽略一些特定標簽,有時可以省略開始或結束標簽。總的來說,它是一種soft語法,不像xml呆板、固執。
顯然,這個看起來很小的差異卻帶來了很大的不同。一方面,這是html流行的原因——它的寬容使web開發人員的工作更加輕松,但另一方面,這也使很難去寫一個格式化的文法。所以,html的解析并不簡單,它既不能用傳統的解析器解析,也不能用xml解析器解析。
HTML DTD
Html適用DTD格式進行定義,這一格式是用于定義SGML家族的語言,包括了對所有允許元素及它們的屬性和層次關系的定義。正如前面提到的,html DTD并沒有生成一種上下文無關文法。
DTD有一些變種,標準模式只遵守規范,而其他模式則包含了對瀏覽器過去所使用標簽的支持,這么做是為了兼容以前內容。最新的標準DTD在http://www.w3.org/TR/html4/strict.dtd
DOM
輸出的樹,也就是解析樹,是由DOM元素及屬性節點組成的。DOM是文檔對象模型的縮寫,它是html文檔的對象表示,作為html元素的外部接口供js等調用。
樹的根是“document”對象。
DOM和標簽基本是一一對應的關系,例如,如下的標簽:
<html>
<body>
<p>
Hello DOM
</p>
<div><img src=”example.png” /></div>
</body>
</html>
it知識庫:前端必讀:瀏覽器內部工作原理,轉載需保留來源!
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播更多信息之目的,如作者信息標記有誤,請第一時間聯系我們修改或刪除,多謝。



