|
|
一、淘寶網的困境
對于淘寶網這樣的大型電子商務網站,對于圖片服務的要求特別的高。而且對于賣家來說,圖片遠勝于文字描述,因此賣家也格外看重圖片的顯示質量、訪問速度等問題。根據淘寶網的流量分析,整個淘寶網流量中,圖片的訪問流量會占到90%以上,而主站的網頁則占到不到10%。同時大量的圖片需要根據不同的應用位置,生成不同大小規格的縮略圖。考慮到多種不同的應用場景以及改版的可能性,一張原圖有可能需要生成20多個不同尺寸規格的縮略圖。
淘寶整體圖片存儲系統容量1800TB(1.8PB),已經占用空間990TB(約1PB)。保存的圖片文件數量達到286億多個,這些圖片文件包括根據原圖生成的縮略圖。平均圖片大小是17.45K;8K以下圖片占圖片數總量的61%,占存儲容量的11%。對于如此大規模的小文件存儲與讀取需要頻繁的尋道和換道,在大量高并發訪問量的情況下,非常容易造成讀取延遲。
2007年之前淘寶采用NETApp公司的文件存儲系統。至2006年, NETApp公司最高端的產品也不能滿足淘寶存儲的要求。首先是商用的存儲系統沒有對小文件存儲和讀取的環境進行有針對性的優化;其次,文件數量大,網絡存儲設備無法支撐;另外,整個系統所連接的服務器也越來越多,網絡連接數已經到達了網絡存儲設備的極限。此外,商用存儲系統擴容成本高,10T的存儲容量需要幾百萬,而且存在單點故障,容災和安全性無法得到很好的保證。
二、淘寶網自主開發的目的
- 商用軟件很難滿足大規模系統的應用需求,無論存儲還是CDN還是負載均衡,因為在廠商實驗室端,很難實現如此大的數據規模測試。
- 研發過程中,將開源和自主開發相結合,會有更好的可控性,系統出問題了,完全可以從底層解決問題,系統擴展性也更高。
- 在一定規模效應基礎上,研發的投入都是值得的。當規模超過交叉點后自主研發才能收到較好的經濟效果。實際上淘寶網的規模已經遠遠超過了交叉點。
- 自主研發的系統可在軟件和硬件多個層次不斷的優化。
三、淘寶TFS的介紹
1、TFS 1.0 版本
從2006年開始,淘寶網決定自己開發一套針對海量小文件存儲難題的文件系統,用于解決自身圖片存儲的難題。到2007年6月,TFS(淘寶文件系統,Taobao File System)正式上線運營。在生產環境中應用的集群規模達到了200臺PC Server(146G*6 SAS 15K Raid5),文件數量達到上億級別;系統部署存儲容量: 140 TB;實際使用存儲容量: 50 TB;單臺支持隨機IOPS 200+,流量3MBps。
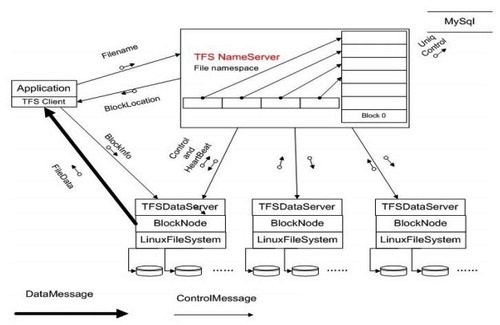
圖為淘寶集群文件系統TFS 1.0第一版的邏輯架構:集群由一對Name Server和多臺Data Server構成,Name Server的兩臺服務器互為雙機,就是集群文件系統中管理節點的概念。
- 每個Data Server運行在一臺普通的Linux主機上
- 以block文件的形式存放數據文件(一般64M一個block)
- block存多份保證數據安全
- 利用ext3文件系統存放數據文件
- 磁盤raid5做數據冗余
- 文件名內置元數據信息,用戶自己保存TFS文件名與實際文件的對照關系–使得元數據量特別小。
TFS最大的特點就是將一部分元數據隱藏到圖片的保存文件名上,大大簡化了元數據,消除了管理節點對整體系統性能的制約,這一理念和目前業界流行的“對象存儲”較為類似。傳統的集群系統里面元數據只有1份,通常由管理節點來管理,因而很容易成為瓶頸。而對于淘寶網的用戶來說,圖片文件究竟用什么名字來保存實際上用戶并不關心,因此TFS在設計規劃上考慮在圖片的保存文件名上暗藏了一些元數據信息,例如圖片的大小、時間、訪問頻次等等信息,包括所在的邏輯塊號。而在元數據上,實際上保存的信息很少,因此元數據結構非常簡單。僅僅只需要一個fileID,能夠準確定位文件在什么地方。由于大量的文件信息都隱藏在文件名中,整個系統完全拋棄了傳統的目錄樹結構,因為目錄樹開銷最大。拿掉后,整個集群的高可擴展性極大提高。
2、 TFS 1.3版本
到2009年6月,TFS 1.3版本上線,集群規模大大擴展,部署到淘寶的圖片生產系統上,整個系統已經從原有200臺PC服務器擴增至440臺PC Server(300G*12 SAS 15K RPM) + 30臺PC Server (600G*12 SAS 15K RPM)。支持文件數量也擴容至百億級別;系統部署存儲容量:1800TB(1.8PB);當前實際存儲容量:995TB;單臺Data Server支持隨機IOPS 900+,流量15MB+;目前Name Server運行的物理內存是217MB(服務器使用千兆網卡)。
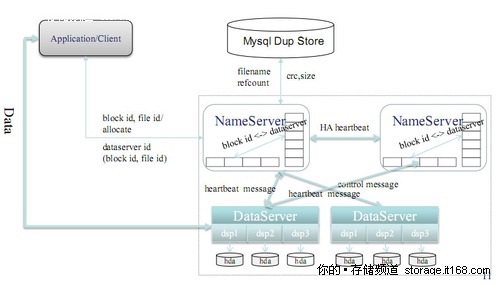
圖為TFS1.3版本的邏輯結構圖,在TFS1.3版本中,淘寶網的軟件工作組重點改善了心跳和同步的性能,最新版本的心跳和同步在幾秒鐘之內就可完成切換,同時進行了一些新的優化:包括元數據存內存上,清理磁盤空間,性能上也做了優化,包括:
- 完全扁平化的數據組織結構,拋棄了傳統文件系統的目錄結構。
- 在塊設備基礎上建立自有的文件系統,減少EXT3等文件系統數據碎片帶來的性能損耗
- 單進程管理單塊磁盤的方式,摒除RAID5機制
- 帶有HA機制的中央控制節點,在安全穩定和性能復雜度之間取得平衡。
- 盡量縮減元數據大小,將元數據全部加載入內存,提升訪問速度。
- 跨機架和IDC的負載均衡和冗余安全策略。
- 完全平滑擴容。
TFS主要的性能參數不是IO吞吐量,而是單臺PCServer提供隨機讀寫IOPS。由于硬件型號不同,很難給出一個參考值來說明性能。但基本上可以達到單塊磁盤隨機IOPS理論最大值的60%左右,整機的輸出隨盤數增加而線性增加。
3、 TFS 2.0 版本
TFS 2.0(下面簡稱TFS,目前已經開源)是一個高可擴展、高可用、高性能、面向互聯網服務的分布式文件系統,主要針對海量的非結構化數據,它構筑在普通的Linux機器集群上,可為外部提供高可靠和高并發的存儲訪問。TFS為淘寶提供海量小文件存儲,通常文件大小不超過1M,滿足了淘寶對小文件存儲的需求,被廣泛地應用在淘寶各項應用中。它采用了HA架構和平滑擴容,保證了整個文件系統的可用性和擴展性。同時扁平化的數據組織結構,可將文件名映射到文件的物理地址,簡化了文件的訪問流程,一定程度上為TFS提供了良好的讀寫性能。
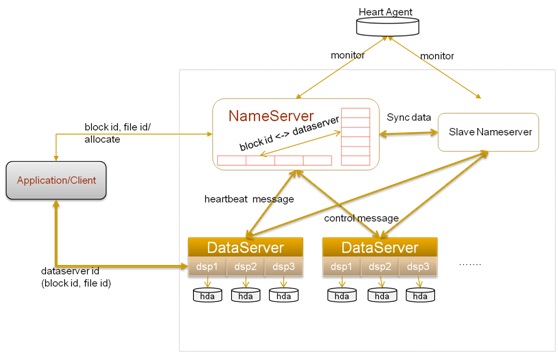
一個TFS集群由兩個!NameServer節點(一主一備)和多個!DataServer節點組成。這些服務程序都是作為一個用戶級的程序運行在普通Linux機器上的。在TFS中,將大量的小文件(實際數據文件)合并成為一個大文件,這個大文件稱為塊(Block), 每個Block擁有在集群內唯一的編號(Block Id), Block Id在!NameServer在創建Block的時候分配, !NameServer維護block與!DataServer的關系。Block中的實際數據都存儲在!DataServer上。而一臺!DataServer服務器一般會有多個獨立!DataServer進程存在,每個進程負責管理一個掛載點,這個掛載點一般是一個獨立磁盤上的文件目錄,以降低單個磁盤損壞帶來的影響。正常情況下,一個塊會在!DataServer上存在,主!NameServer負責Block的創建,刪除,復制,均衡,整理, !NameServer不負責實際數據的讀寫,實際數據的讀寫由!DataServer完成。
- !NameServer主要功能是: 管理維護Block和!DataServer相關信息,包括!DataServer加入,退出, 心跳信息, block和!DataServer的對應關系建立,解除。
- !DataServer主要功能是: 負責實際數據的存儲和讀寫。
同時為了考慮容災,!NameServer采用了HA結構,即兩臺機器互為熱備,同時運行,一臺為主,一臺為備,主機綁定到對外vip,提供服務;當主機器宕機后,迅速將vip綁定至備份!NameServer,將其切換為主機,對外提供服務。圖中的HeartAgent就完成了此功能。
TFS的塊大小可以通過配置項來決定,通常使用的塊大小為64M。TFS的設計目標是海量小文件的存儲,所以每個塊中會存儲許多不同的小文件。!DataServer進程會給Block中的每個文件分配一個ID(File ID,該ID在每個Block中唯一),并將每個文件在Block中的信息存放在和Block對應的Index文件中。這個Index文件一般都會全部load在內存,除非出現!DataServer服務器內存和集群中所存放文件平均大小不匹配的情況。
另外,還可以部署一個對等的TFS集群,作為當前集群的輔集群。輔集群不提供來自應用的寫入,只接受來自主集群的寫入。當前主集群的每個數據變更操作都會重放至輔集群。輔集群也可以提供對外的讀,并且在主集群出現故障的時候,可以接管主集群的工作。
平滑擴容
原有TFS集群運行一定時間后,集群容量不足,此時需要對TFS集群擴容。由于DataServer與NameServer之間使用心跳機制通信,如果系統擴容,只需要將相應數量的新!DataServer服務器部署好應用程序后啟動即可。這些!DataServer服務器會向!NameServer進行心跳匯報。!NameServer會根據!DataServer容量的比率和!DataServer的負載決定新數據寫往哪臺!DataServer的服務器。根據寫入策略,容量較小,負載較輕的服務器新數據寫入的概率會比較高。同時,在集群負載比較輕的時候,!NameServer會對!DataServer上的Block進行均衡,使所有!DataServer的容量盡早達到均衡。
進行均衡計劃時,首先計算每臺機器應擁有的blocks平均數量,然后將機器劃分為兩堆,一堆是超過平均數量的,作為移動源;一類是低于平均數量的,作為移動目的。
移動目的的選擇:首先一個block的移動的源和目的,應該保持在同一網段內,也就是要與另外的block不同網段;另外,在作為目的的一定機器內,優先選擇同機器的源到目的之間移動,也就是同臺!DataServer服務器中的不同!DataServer進程。
當有服務器故障或者下線退出時(單個集群內的不同網段機器不能同時退出),不影響TFS的服務。此時!NameServer會檢測到備份數減少的Block,對這些Block重新進行數據復制。
在創建復制計劃時,一次要復制多個block, 每個block的復制源和目的都要盡可能的不同,并且保證每個block在不同的子網段內。因此采用輪換選擇(roundrobin)算法,并結合加權平均。
由于DataServer之間的通信是主要發生在數據寫入轉發的時候和數據復制的時候,集群擴容基本沒有影響。假設一個Block為64M,數量級為1PB。那么NameServer上會有 1 * 1024 * 1024 * 1024 / 64 = 16.7M個block。假設每個Block的元數據大小為0.1K,則占用內存不到2G。
存儲機制
在TFS中,將大量的小文件(實際用戶文件)合并成為一個大文件,這個大文件稱為塊(Block)。TFS以Block的方式組織文件的存儲。每一個Block在整個集群內擁有唯一的編號,這個編號是由NameServer進行分配的,而DataServer上實際存儲了該Block。在!NameServer節點中存儲了所有的Block的信息,一個Block存儲于多個!DataServer中以保證數據的冗余。對于數據讀寫請求,均先由!NameServer選擇合適的!DataServer節點返回給客戶端,再在對應的!DataServer節點上進行數據操作。!NameServer需要維護Block信息列表,以及Block與!DataServer之間的映射關系,其存儲的元數據結構如下:
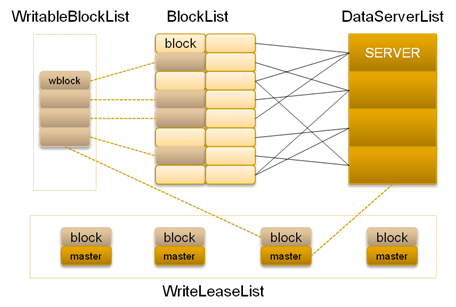
在!DataServer節點上,在掛載目錄上會有很多物理塊,物理塊以文件的形式存在磁盤上,并在!DataServer部署前預先分配,以保證后續的訪問速度和減少碎片產生。為了滿足這個特性,!DataServer現一般在EXT4文件系統上運行。物理塊分為主塊和擴展塊,一般主塊的大小會遠大于擴展塊,使用擴展塊是為了滿足文件更新操作時文件大小的變化。每個Block在文件系統上以“主塊+擴展塊”的方式存儲。每一個Block可能對應于多個物理塊,其中包括一個主塊,多個擴展塊。
在DataServer端,每個Block可能會有多個實際的物理文件組成:一個主Physical Block文件,N個擴展Physical Block文件和一個與該Block對應的索引文件。Block中的每個小文件會用一個block內唯一的fileid來標識。!DataServer會在啟動的時候把自身所擁有的Block和對應的Index加載進來。
容錯機制
集群容錯。TFS可以配置主輔集群,一般主輔集群會存放在兩個不同的機房。主集群提供所有功能,輔集群只提供讀。主集群會把所有操作重放到輔集群。這樣既提供了負載均衡,又可以在主集群機房出現異常的情況不會中斷服務或者丟失數據。
!NameServer容錯。Namserver主要管理了!DataServer和Block之間的關系。如每個!DataServer擁有哪些Block,每個Block存放在哪些!DataServer上等。同時,!NameServer采用了HA結構,一主一備,主NameServer上的操作會重放至備NameServer。如果主NameServer出現問題,可以實時切換到備NameServer。另外!NameServer和!DataServer之間也會有定時的heartbeat,!DataServer會把自己擁有的Block發送給!NameServer。!NameServer會根據這些信息重建!DataServer和Block的關系。
!DataServer容錯。TFS采用Block存儲多份的方式來實現!DataServer的容錯。每一個Block會在TFS中存在多份,一般為3份,并且分布在不同網段的不同!DataServer上。對于每一個寫入請求,必須在所有的Block寫入成功才算成功。當出現磁盤損壞!DataServer宕機的時候,TFS啟動復制流程,把備份數未達到最小備份數的Block盡快復制到其他DataServer上去。 TFS對每一個文件會記錄校驗crc,當客戶端發現crc和文件內容不匹配時,會自動切換到一個好的block上讀取。此后客戶端將會實現自動修復單個文件損壞的情況。
并發機制
對于同一個文件來說,多個用戶可以并發讀。現有TFS并不支持并發寫一個文件。一個文件只會有一個用戶在寫。這在TFS的設計里面對應著是一個block同時只能有一個寫或者更新操作。
TFS文件名的結構
TFS的文件名由塊號和文件號通過某種對應關系組成,最大長度為18字節。文件名固定以T開始,第二字節為該集群的編號(可以在配置項中指定,取值范圍 1~9)。余下的字節由Block ID和File ID通過一定的編碼方式得到。文件名由客戶端程序進行編碼和解碼,它映射方式如下圖:
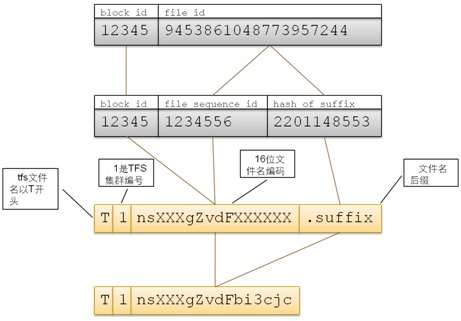
TFS客戶程序在讀文件的時候通過將文件名轉換為BlockID和FileID信息,然后可以在!NameServer取得該塊所在!DataServer信息(如果客戶端有該Block與!DataServere的緩存,則直接從緩存中取),然后與!DataServer進行讀取操作。
四、圖片服務器部署與緩存
下圖為淘寶網整體系統的拓撲圖結構。整個系統就像一個龐大的服務器一樣,有處理單元、緩存單元和存儲單元。前面已經詳細介紹過了后臺的TFS集群文件存儲系統,在TFS前端,還部署著200多臺圖片文件服務器,用Apache實現,用于生成縮略圖的運算。
根據淘寶網的縮略圖生成規則,縮略圖都是實時生成的。這樣做的好處有兩點:一是為了避免后端圖片服務器上存儲的圖片數量過多,大大節約后臺存儲空間的需求,淘寶網計算,采用實時生成縮略圖的模式比提前全部生成好縮略圖的模式節約90%的存儲空間,也就是說,存儲空間只需要后一種模式的10%;二是,縮略圖可根據需要實時生成出來,更為靈活。
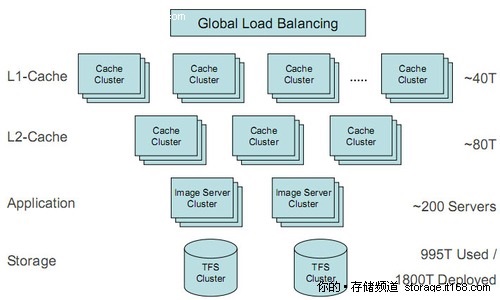
淘寶網圖片存儲與處理系統全局拓撲,圖片服務器前端還有一級和二級緩存服務器,盡量讓圖片在緩存中命中,最大程度的避免圖片熱點,實際上后端到達TFS的流量已經非常離散和平均。
圖片文件服務器的前端則是一級緩存和二級緩存,前面還有全局負載均衡的設置,解決圖片的訪問熱點問題。圖片的訪問熱點一定存在,重要的是,讓圖片盡量在緩存中命中。目前淘寶網在各個運營商的中心點設有二級緩存,整體系統中心店設有一級緩存,加上全局負載均衡,傳遞到后端TFS的流量就已經非常均衡和分散了,對前端的響應性能也大大提高。
根據淘寶的緩存策略,大部分圖片都盡量在緩存中命中,如果緩存中無法命中,則會在本地服務器上查找是否存有原圖,并根據原圖生成縮略圖,如果都沒有命中,則會考慮去后臺TFS集群文件存儲系統上調取,因此,最終反饋到TFS集群文件存儲系統上的流量已經被大大優化了。
淘寶網將圖片處理與緩存編寫成基于Nginx的模塊(Nginx-tfs),淘寶認為Nginx是目前性能最高的HTTP服務器(用戶空間),代碼清晰,模塊化非常好。淘寶使用GraphicsMagick進行圖片處理,采用了面向小對象的緩存文件系統,前端有LVS+Haproxy將原圖和其所有縮略圖請求都調度到同一臺Image Server。
文件定位上,內存用hash算法做索引,最多一次讀盤。寫盤方式則采用Append方式寫,并采用了淘汰策略FIFO,主要考慮降低硬盤的寫操作,沒有必要進一步提高Cache命中率,因為Image Server和TFS在同一個數據中心,讀盤效率還是非常高的。
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播更多信息之目的,如作者信息標記有誤,請第一時間聯系我們修改或刪除,多謝。



