|
|
Apache Hadoop是一個(gè)用于構(gòu)建大規(guī)模,共享存儲(chǔ)和計(jì)算基礎(chǔ)設(shè)施的軟件框架,Hadoop集群經(jīng)常用于各種研究和開發(fā)項(xiàng)目,如Yahoo!,eBay,F(xiàn)acebook,Twitter等互聯(lián)網(wǎng)公司就大量使用了Hadoop,并在核心業(yè)務(wù)系統(tǒng)中扮演中關(guān)鍵角色,因此正確部署Hadoop集群是確保獲得最佳投資回報(bào)的關(guān)鍵。
本文介紹了在Apache Hadoop上運(yùn)行應(yīng)用程序的最佳實(shí)踐,實(shí)際上,我們引入了網(wǎng)格模式(Grid Pattern)的概念,它和設(shè)計(jì)模式類似,它代表運(yùn)行在網(wǎng)格(Grid)上的應(yīng)用程序的可復(fù)用解決方案。
概述
Hadoop上的應(yīng)用程序數(shù)據(jù)是使用Map-Reduce(映射-化簡)范式寫入的,Map-Reduce作業(yè)通常要將輸入數(shù)據(jù)集拆分成獨(dú)立的數(shù)據(jù)塊,由Map任務(wù)以完全并行的方式處理,框架對(duì)Map的輸出結(jié)果排序,然后傳遞給Reduce任務(wù),通常情況下,作業(yè)的輸入和輸出結(jié)果都保存在文件系統(tǒng)上,框架管理計(jì)劃任務(wù),監(jiān)控它們的執(zhí)行情況,以及重新執(zhí)行失敗的任務(wù)。
Map-Reduce應(yīng)用程序指定輸入/輸出位置,通過實(shí)現(xiàn)適當(dāng)?shù)腍adoop接口,如Mapper和Reducer,分別提供Map和Reduce功能,它們和其它作業(yè)參數(shù)一起構(gòu)成作業(yè)配置。Hadoop作業(yè)客戶端將作業(yè)(jar/可執(zhí)行文件等)和配置提交給JobTracker,JobTracker承擔(dān)起分配軟件/配置,調(diào)度任務(wù)和監(jiān)控的職責(zé),為作業(yè)客戶端提供狀態(tài)和診斷信息。
Map/Reduce框架工作在(鍵/值)對(duì)上,也就是說,框架將給作業(yè)的輸入看作是一對(duì),并產(chǎn)生一對(duì)作為作業(yè)的輸出,當(dāng)然輸入輸出的類型可能是不同的。
下面是Map/Reduce應(yīng)用程序中常見的數(shù)據(jù)流:
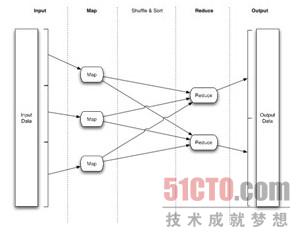
圖1: Map/Reduce應(yīng)用程序中的數(shù)據(jù)流
絕大多數(shù)Map-Reduce應(yīng)用程序都在網(wǎng)格上執(zhí)行,不會(huì)直接實(shí)現(xiàn)低級(jí)的Map-Reduce接口,相反,它們使用高級(jí)語言,如Pig實(shí)現(xiàn)。
Oozie是網(wǎng)格上完美的工作流管理和調(diào)度解決方案,它支持多種接口(Hadoop Map-Reduce,Pig,Hadoop Streaming和Hadoop Pipes等),并可以根據(jù)時(shí)間或數(shù)據(jù)可用性實(shí)現(xiàn)應(yīng)用程序的調(diào)度。
網(wǎng)格模式
這部分內(nèi)容涉及在網(wǎng)格上運(yùn)行Map-Reduce應(yīng)用程序的最佳實(shí)踐。
輸入
Hadoop Map-Reduce專門為處理大批量數(shù)據(jù)做了優(yōu)化,Map通常使用并行方式處理數(shù)據(jù),至少1個(gè)HDFS數(shù)據(jù)塊,也就是說每次最少要處理128MB的數(shù)據(jù)。
◆默認(rèn)情況下,這個(gè)框架每個(gè)Map至少要處理1個(gè)HDFS文件,這意味著如果某個(gè)應(yīng)用程序要處理非常大的輸入文件,最好是通過一種特殊的輸入格式,如MultiFileInputFormat,讓每個(gè)Map處理多個(gè)文件,即便是在處理為數(shù)不多的小型輸入文件時(shí)也理應(yīng)如此,每個(gè)Map處理多個(gè)文件可以大大提高效率。
◆如果應(yīng)用程序需要處理大量的數(shù)據(jù),即使它們存在于大型文件中,每個(gè)Map處理超過128MB的數(shù)據(jù)也會(huì)更快。
網(wǎng)格模式:在少量Map中聚合處理多個(gè)小型輸入文件,使用更大的HDFS塊大小處理超大型數(shù)據(jù)集。
Map(映射)
Map的數(shù)量通常是由輸入的總大小決定的,即所有輸入文件的總數(shù)據(jù)塊數(shù),因此,如果你要處理10TB輸入數(shù)據(jù),塊大小128MB,那么總共需要82000個(gè)Map。
任務(wù)設(shè)置需要一段時(shí)間,因此執(zhí)行大型作業(yè)時(shí),Map至少需要一分鐘。正如前面提到的,讓每個(gè)Map同時(shí)處理多個(gè)文件效率會(huì)更高,因此,如果應(yīng)用程序要處理超大型輸入文件,讓每個(gè)Map處理更大的數(shù)據(jù)塊更有效,例如,讓每個(gè)Map處理更多數(shù)據(jù)的一個(gè)方法是讓應(yīng)用程序處理更大的HDFS數(shù)據(jù)塊,如512MB或盡可能更大。
作為一個(gè)極端的例子,Map-Reduce開發(fā)團(tuán)隊(duì)使用大約66000個(gè)Map完成了PB級(jí)數(shù)據(jù)的排序(PetaSort),也就是說,66000個(gè)Map處理了1PB數(shù)據(jù)(每個(gè)Map負(fù)責(zé)12.5GB)。但太多的Map在很短的時(shí)間內(nèi)同時(shí)運(yùn)行很容易造成反效果。
網(wǎng)格模式:除非應(yīng)用程序的Map有嚴(yán)重的CPU限制,單個(gè)應(yīng)用程序幾乎沒有任何理由需要超過60000-7000個(gè)Map。同樣,當(dāng)Map處理更大的數(shù)據(jù)塊時(shí),重要的是確保它們有足夠的內(nèi)存,以便排序緩沖區(qū)加速M(fèi)ap端排序(請(qǐng)閱讀參考文檔的io.sort.mb和io.sort.record.percent小節(jié)),如果Map輸出可以直接在Map的排序緩沖區(qū)中處理,應(yīng)用程序的性能可以大大提高,Map JVM必須承擔(dān)更大的堆大小,重要的是要記住內(nèi)存中去除序列化的輸入大小和在磁盤上的大小可能有很大的不同,在這種情況下,應(yīng)用程序需要更大的堆大小確保Map輸入記錄和Map輸出記錄可以保持在內(nèi)存中。
網(wǎng)格模式:確保Map大小合適,以便所有Map輸出可以保持在排序緩沖區(qū)中。
Map數(shù)量合適對(duì)應(yīng)用程序有以下這些好處:
◆減少調(diào)度開銷,更少的Map意味著任務(wù)調(diào)度也更簡單,集群的可用性也更高;
◆Map端更高效,因?yàn)橛凶銐虻膬?nèi)存容納Map輸出;
◆減少了從Map向Reduce清洗Map輸出需要的查找次數(shù),記住每個(gè)Map為每個(gè)Reduce產(chǎn)生輸出,因此查找次數(shù)等m*r,m表示Map數(shù)量,r表示Reduce數(shù)量。
◆每個(gè)清洗的片段更大,減少了建立連接的開銷;
◆Reduce端合并了排序后的Map輸出,效率更高,因?yàn)樾枰喜⒌腗ap輸出片段更少了。
值得注意的是,每個(gè)Map處理太多的數(shù)據(jù)可能并不完全是好事,至少對(duì)故障恢復(fù)來說會(huì)很麻煩,即使是單點(diǎn)Map故障,也會(huì)造成嚴(yán)重的應(yīng)用程序延遲。
網(wǎng)格模式:應(yīng)用程序應(yīng)使用較少的Map并行處理數(shù)據(jù),確保不會(huì)出現(xiàn)糟糕的故障恢復(fù)情況。
合并器(Combiner)
合理使用合并器,應(yīng)用程序可以獲得更好的聚合效果,合并器最大的優(yōu)勢在于可以大大減少從Map到Reduce清洗的數(shù)據(jù)量。
清洗(Shuffle)
雖然使用合并器會(huì)得到更好的聚合效果,但它存在性能問題,因?yàn)樗枰袚?dān)起額外的Map輸出記錄序列化/反序列化任務(wù),應(yīng)用程序可以使用合并器輸入/輸出記錄計(jì)數(shù)器測量合并器的效率。
網(wǎng)格模式:合并器可以幫助應(yīng)用程序減少清洗階段的網(wǎng)絡(luò)流量,但最重要的是要確保合并器要提供足夠的聚合能力。
Reduce(化簡)
Reduce的效率很大程度上是由清洗的性能決定的,應(yīng)用程序配置的Reduce數(shù)量也很關(guān)鍵,太多或過少的Reduce都會(huì)產(chǎn)生反效果。
◆太少的Reduce會(huì)給節(jié)點(diǎn)造成負(fù)載過重,我曾看到最極端的情況,每個(gè)Reduce負(fù)責(zé)處理超過100GB的數(shù)據(jù),同樣,也會(huì)使故障恢復(fù)變得很困難,因?yàn)榧幢闶菃蝹€(gè)Reduce故障也會(huì)引起顯著的作業(yè)延遲。
◆太多的Reduce會(huì)給清洗閂帶來不利影響,同樣,在極端情況下,它會(huì)創(chuàng)建太多的小文件作為作業(yè)的輸出,這會(huì)影響到應(yīng)用程序以后處理小文件性能。
網(wǎng)格模式:應(yīng)用程序應(yīng)該確保每個(gè)Reduce最少可以處理1-2GB數(shù)據(jù),最多5-10GB數(shù)據(jù)。
輸出
一個(gè)關(guān)鍵因素是要記住應(yīng)用程序的輸出數(shù)量是和配置的Reduce數(shù)量呈線性關(guān)系的,正如前面提到的,配置數(shù)量適當(dāng)?shù)腞educe是非常重要的。此外,還需要考慮一些其它因素:
◆使用壓縮程序?qū)?a href=/pingce/yingyong/ target=_blank class=infotextkey>應(yīng)用程序的輸出做適當(dāng)?shù)膲嚎s,提高HDFS寫入性能;
◆每個(gè)Reduce不止輸出一個(gè)輸出文件,可以避免使用側(cè)文件(side-file),應(yīng)用程序通常會(huì)寫一些側(cè)文件來捕捉統(tǒng)計(jì)數(shù)據(jù),如果所收集的統(tǒng)計(jì)數(shù)據(jù)很小,計(jì)數(shù)器可能更合適;
◆為Reduce輸出使用合適的文件格式,對(duì)下游用戶來說,使用zlib/gzip/lzo等編碼器輸出大量的文本壓縮數(shù)據(jù)會(huì)適得其反,因?yàn)檫@些格式的文件無法再拆分,Map-Reduce框架必須強(qiáng)制單個(gè)Map處理整個(gè)文件,這會(huì)使負(fù)載均衡變得非常糟糕,并導(dǎo)致故障恢復(fù)變得很困難。應(yīng)該使用SequenceFile和TFile格式緩解這些問題,因?yàn)樗鼈兗仁强蓧嚎s的,又是可以再拆分的。
◆當(dāng)獨(dú)立輸出文件很大時(shí)(數(shù)GB),最好使用更大的輸出塊大小(dfs.block.size)。
網(wǎng)格模式:應(yīng)用程序輸出少量的大文件,每個(gè)文件橫跨多個(gè)HDFS塊,并經(jīng)過適當(dāng)?shù)膲嚎s。
分布式緩存(DistributedCache)
分布式緩存高效分發(fā)應(yīng)用程序相關(guān)的大型只讀文件,它是Map-Reduce框架為應(yīng)用程序緩存文件(文本,壓縮文件,jar等)提供的一種手段,任何任務(wù)在從屬節(jié)點(diǎn)上執(zhí)行之前,Map-Reduce框架將會(huì)把必要的文件拷貝到從屬節(jié)點(diǎn)上,其高效源于這些文件只會(huì)被復(fù)制一次,并提供從屬節(jié)點(diǎn)上未壓縮文件的緩存能力,它可以在Map或Reduce任務(wù)中作為一個(gè)最基本的軟件分發(fā)機(jī)制,用于分發(fā)jar和本地庫文件,只需要設(shè)定classpath或本地庫路徑即可。
分布式緩存被設(shè)計(jì)為主要用于分發(fā)少量中等規(guī)模的文件,大小從幾MB到幾十MB,分布式緩存當(dāng)前實(shí)現(xiàn)的一個(gè)缺點(diǎn)是無法指定Map或Reduce的相關(guān)的產(chǎn)物(文件)。
在極少數(shù)情況下,由任務(wù)本身復(fù)制這些產(chǎn)物可能更恰當(dāng),例如,如果應(yīng)用程序只配有少量Reduce,但需要分布式緩存中非常大型的產(chǎn)物(如大于512MB)。
網(wǎng)格模式:應(yīng)用程序應(yīng)該確保分布式緩存中的產(chǎn)物不能要求過多的I/O,不能多于應(yīng)用程序任務(wù)真實(shí)的輸入。
計(jì)數(shù)器(Counters)
這里指的是全局計(jì)數(shù)器,由Map/Reduce框架或應(yīng)用程序定義,應(yīng)用程序可以定義任意的計(jì)數(shù)器,然后在Map和/或Reduce方法中更新,這些計(jì)數(shù)器再通過框架進(jìn)行全局匯總。
計(jì)數(shù)器應(yīng)以跟蹤少量的,重要的全局信息為妥,它們絕不是為了聚合非常細(xì)粒度的應(yīng)用程序統(tǒng)計(jì)數(shù)據(jù)。
計(jì)數(shù)器代價(jià)非常高,因?yàn)镴obTracker必須在整個(gè)應(yīng)用程序生命周期維護(hù)每個(gè)Map/Reduce任務(wù)的計(jì)數(shù)器。
網(wǎng)格模式:應(yīng)用程序不應(yīng)該使用超過10,15或25個(gè)自定義計(jì)數(shù)器。
壓縮
Hadoop Map-Reduce為應(yīng)用程序中間Map輸出和應(yīng)用程序輸出結(jié)果提供壓縮,也就是說可以減少輸出結(jié)果大小。
中間輸出壓縮:正如前面講到的,采用適當(dāng)?shù)膲嚎s編碼對(duì)中間Map輸出結(jié)果進(jìn)行壓縮,可以減少M(fèi)ap和Reduce之間的網(wǎng)絡(luò)流量,從而提高性能,Lzo是壓縮Map輸出結(jié)果的理想選擇,因?yàn)樗诟逤PU效率下提供了很好的壓縮比。
應(yīng)用程序輸出壓縮:采用適當(dāng)?shù)膲嚎s編碼和文件格式對(duì)應(yīng)用程序輸出結(jié)果進(jìn)行壓縮,可以提供更好的應(yīng)用程序延遲,在大多數(shù)情況下,Zlib/Gzip可能是較好的選擇,因?yàn)樗鼈冊(cè)诤侠淼乃俣认绿峁┝烁邏嚎s率,bzip2通常用于對(duì)壓縮速度要求不要的情景。
全序輸出(抽樣)
有時(shí)應(yīng)用程序需要產(chǎn)生全序輸出,也就是說輸出結(jié)果要全部排好序,在這種情況下,應(yīng)用程序常用的一個(gè)反模式是使用單個(gè)Reduce,強(qiáng)制單一的全局聚合,很明顯,這樣做是非常低效的,不僅使Reduce任務(wù)所在的單個(gè)節(jié)點(diǎn)上的負(fù)載很重,也使故障恢復(fù)變得很困難。
更好的辦法是對(duì)輸入抽樣,用抽樣結(jié)果驅(qū)動(dòng)采樣分區(qū)程序,而不是默認(rèn)的散列分區(qū)程序,這樣才可以提供更好的負(fù)載均衡和故障恢復(fù)能力。
連接全序數(shù)據(jù)集
在網(wǎng)格上需要注意的另一個(gè)要素是連接兩個(gè)全序數(shù)據(jù)集,注意,它們和基數(shù)可能不是精確的倍數(shù)關(guān)系,例如,一個(gè)數(shù)據(jù)集有512個(gè) Bucket,而其它數(shù)據(jù)集只有200個(gè)Bucket。
在這種情況下,確保輸入數(shù)據(jù)是全序的,這樣應(yīng)用程序就可以使用數(shù)據(jù)集的基數(shù),Pig以高效的方式處理這些連接。
HDFS操作&JobTracker操作
NameNode是一個(gè)寶貴的資源,在網(wǎng)格中執(zhí)行HDFS操作時(shí),應(yīng)用程序需要謹(jǐn)慎,特別是,我們不鼓勵(lì)應(yīng)用程序做非I/O操作,即Map/Reduce任務(wù)中的元數(shù)據(jù)操作,如遞歸統(tǒng)計(jì),統(tǒng)計(jì)大型目錄等。
同樣,應(yīng)用程序不應(yīng)該為集群統(tǒng)計(jì)從后端聯(lián)系JobTracker。
網(wǎng)格模式:應(yīng)用程序不應(yīng)該從后端在文件系統(tǒng)上執(zhí)行任何元數(shù)據(jù)操作,他們應(yīng)限制到作業(yè)提交期間的作業(yè)客戶端,此外,應(yīng)用程序不應(yīng)該從后端聯(lián)系JobTracker。
用戶日志
用戶任務(wù)日志,即Map/Reduce任務(wù)的srdout和stderr,存儲(chǔ)在任務(wù)執(zhí)行所在計(jì)算節(jié)點(diǎn)的本地磁盤上。
由于節(jié)點(diǎn)是共享基礎(chǔ)設(shè)施的一部分,Map/Reduce框架限制了存儲(chǔ)在節(jié)點(diǎn)上的任務(wù)日志數(shù)量。
Web用戶界面
Hadoop Map/Reduce框架提供了一個(gè)基本的Web用戶界面通過JobTracker跟蹤運(yùn)行中的作業(yè),它們的進(jìn)度和已完成作業(yè)歷史等。
最重要的是要記住Web用戶界面是提供給人使用的,而不是為自動(dòng)化過程提供的。
實(shí)現(xiàn)自動(dòng)化過程抓取Web用戶界面是被嚴(yán)格禁止的,Web用戶界面中的某些部件,如瀏覽作業(yè)歷史,在JobTracker上是非常耗資源的,可能會(huì)導(dǎo)致嚴(yán)重的性能問題。
如果確實(shí)需要自動(dòng)統(tǒng)計(jì)收集數(shù)據(jù),最好咨詢網(wǎng)格解決方案提供商,網(wǎng)格SE,或Map-Reduce開發(fā)團(tuán)隊(duì)。
工作流
Oozie是網(wǎng)格首選的工作流管理和調(diào)度系統(tǒng),它可以基于時(shí)間或數(shù)據(jù)可用性管理工作流和提供調(diào)度方案,漸漸地,延遲敏感的生產(chǎn)作業(yè)管線也通過Oozie進(jìn)行管理和調(diào)度。
設(shè)計(jì)Oozie工作流時(shí)需要牢記的一點(diǎn)是,Hadoop更適合批處理超大型數(shù)據(jù),同樣,從處理角度來看,工作流最好是由少量中到大型Map-Reduce作業(yè)組成,而不是由大量的小型Map-Reduce作業(yè)組成,作為一個(gè)極端的例子,我們?cè)吹竭^一個(gè)工作流由數(shù)千個(gè)作業(yè)組成的情景,這是一個(gè)很明顯的反模式,就目前而言,Hadoop框架并不真正適合這種性質(zhì)的業(yè)務(wù),最好是將這些數(shù)以千計(jì)的Map-Reduce作業(yè)減少到合適的數(shù)量,這將有助于提高工作流性能,減少延遲。
網(wǎng)格模式:工作流中的單個(gè)Map-Reduce作業(yè)至少應(yīng)該處理幾十GB數(shù)據(jù)。
反模式
這一部分介紹一些在網(wǎng)格上運(yùn)行的應(yīng)用程序常見的反模式,通常它們不符合大規(guī)模,分布式,批量數(shù)據(jù)處理系統(tǒng)的精神。應(yīng)用程序開發(fā)人員需要引起注意,因?yàn)榫W(wǎng)格軟件堆棧正變得硬化,特別是即將發(fā)布的20.Fred,一些常見的反模式如下:
◆應(yīng)用程序不使用如Pig等高級(jí)接口,除非確有必要。
◆處理成千上萬的小文件(大小小于1 HDFS塊,通常是128MB),使用一個(gè)Map處理單個(gè)小文件。
◆使用小的HDFS塊大小(即128MB)處理非常大的數(shù)據(jù)集,導(dǎo)致需要數(shù)以萬計(jì)的Map。
◆有大量Map(數(shù)千)的應(yīng)用程序運(yùn)行時(shí)很短(如5s)。
◆不使用合并器進(jìn)行直接聚合。
◆應(yīng)用程序Map數(shù)大于60000-70000個(gè)。
◆應(yīng)用程序用很少的Reduce(如1個(gè))處理大型數(shù)據(jù)集。
◆Pig腳本未用PARALLEL關(guān)鍵字處理大型數(shù)據(jù)集。
◆應(yīng)用程序使用單個(gè)Reduce為輸出記錄實(shí)現(xiàn)全排序。
◆應(yīng)用程序使用大量的Reduce處理數(shù)據(jù),每個(gè)Reduce處理不到1-2GB數(shù)據(jù)。
◆應(yīng)用程序?yàn)槊總€(gè)Reduce輸出多個(gè)小型輸出文件。
◆應(yīng)用程序使用分布式緩存分發(fā)大量產(chǎn)物和/或非常大的產(chǎn)物(每一個(gè)數(shù)千MB)。
◆應(yīng)用程序?yàn)槊總€(gè)任務(wù)使用數(shù)十個(gè)或數(shù)千個(gè)計(jì)數(shù)器。
◆應(yīng)用程序從Map/Reduce任務(wù)在文件系統(tǒng)上執(zhí)行元數(shù)據(jù)操作(如listStatus)。
◆應(yīng)用程序?yàn)殛?duì)列/作業(yè)的狀態(tài)抓取JobTracker Web用戶界面,或更糟的是已完成作業(yè)的歷史。
◆工作流由數(shù)千個(gè)處理少量數(shù)據(jù)的小型作業(yè)組成。
it知識(shí)庫:Apache Hadoop最佳實(shí)踐和反模式,轉(zhuǎn)載需保留來源!
鄭重聲明:本文版權(quán)歸原作者所有,轉(zhuǎn)載文章僅為傳播更多信息之目的,如作者信息標(biāo)記有誤,請(qǐng)第一時(shí)間聯(lián)系我們修改或刪除,多謝。



