|
|
前兩天在網上看到世界知名的電騾服務器Razorback 2被查封、4人被拘禁的消息,深感當前做eMule / BitTorrent等P2P文件交換軟件的不易。以分布式哈希表方式(DHT,Distributed Hash Table)來代替集中索引服務器可以說是目前可以預見到的為數不多的P2P軟件發(fā)展趨勢之一,比較典型的方案主要包括:CAN、CHORD、Tapestry、Pastry、Kademlia和Viceroy等,而Kademlia協議則是其中應用最為廣泛、原理和實現最為實用、簡潔的一種,當前主流的P2P軟件無一例外地采用了它作為自己的輔助檢索協議,如eMule、Bitcomet、Bitspirit和Azureus等。鑒于Kademlia日益增長的強大影響力,今天特地在blog里寫下這篇小文,算是對其相關知識系統的總結。
1. Kademlia簡述
Kademlia(簡稱Kad)屬于一種典型的結構化P2P覆蓋網絡(Structured P2P Overlay NETwork),以分布式的應用層全網方式來進行信息的存儲和檢索是其嘗試解決的主要問題。在Kademlia網絡中,所有信息均以<key, value>的哈希表條目形式加以存儲,這些條目被分散地存儲在各個節(jié)點上,從而以全網方式構成一張巨大的分布式哈希表。我們可以形象地把這張哈希大表看成是一本字典:只要知道了信息索引的key,我們便可以通過Kademlia協議來查詢其所對應的value信息,而不管這個value信息究竟是存儲在哪一個節(jié)點之上。在eMule、BitTorrent等P2P文件交換系統中,Kademlia主要充當了文件信息檢索協議這一關鍵角色,但Kad網絡的應用并不僅限于文件交換。下文的描述將主要圍繞eMule中Kad網絡的設計與實現展開。
2. eMule的Kad網絡中究竟存儲了哪些信息?
只要是能夠表述成為<key, value>字典條目形式的信息Kad網絡均能存儲,一個Kad網絡能夠同時存儲多張分布式哈希表。以eMule為例,在任一時刻,其Kad網絡均存儲并維護著兩張分布式哈希表,一張我們可以將其命名為關鍵詞字典,而另一張則可以稱之為文件索引字典。
a. 關鍵詞字典:主要用于根據給出的關鍵詞查詢其所對應的文件名稱及相關文件信息,其中key的值等于所給出的關鍵詞字符串的160比特SHA1散列,而其對應的value則為一個列表,在這個列表當中,給出了所有的文件名稱當中擁有對應關鍵詞的文件信息,這些信息我們可以簡單地用一個3元組條目表示:(文件名,文件長度,文件的SHA1校驗值),舉個例子,假定存在著一個文件“warcraft_frozen_throne.iso”,當我們分別以“warcraft”、“frozen”、“throne”這三個關鍵詞來查詢Kad時,Kad將有可能分別返回三個不同的文件列表,這三個列表的共同之處則在于它們均包含著一個文件名為“warcraft_frozen_throne.iso”的信息條目,通過該條目,我們可以獲得對應iso文件的名稱、長度及其160比特的SHA1校驗值。
b. 文件索引字典:用于根據給出的文件信息來查詢文件的擁有者(即該文件的下載服務提供者),其中key的值等于所需下載文件的SHA1校驗值(這主要是因為,從統計學角度而言,160比特的SHA1文件校驗值可以唯一地確定一份特定數據內容的文件);而對應的value也是一個列表,它給出了當前所有擁有該文件的節(jié)點的網絡信息,其中的列表條目我們也可以用一個3元組表示:(擁有者IP,下載偵聽端口,擁有者節(jié)點ID),根據這些信息,eMule便知道該到哪里去下載具備同一SHA1校驗值的同一份文件了。
3. 利用Kad網絡搜索并下載文件的基本流程是怎樣的?
基于我們對eMule的Kad網絡中兩本字典的理解,利用Kad網絡搜索并下載某一特定文件的基本過程便很明白了,仍以“warcraft_frozen_throne.iso”為例,首先我們可以通過warcraft、frozen、throne等任一關鍵詞查詢關鍵詞字典,得到該iso的SHA1校驗值,然后再通過該校驗值查詢Kad文件索引字典,從而獲得所有提供“warcraft_frozen_throne.iso”下載的網絡節(jié)點,繼而以分段下載方式去這些節(jié)點下載整個iso文件。
在上述過程中,Kad網絡實際上所起的作用就相當于兩本字典,但值得再次指出的是,Kad并不是以集中的索引服務器(如華語P2P源動力、Razorback 2、DonkeyServer 等,騾友們應該很熟悉吧)方式來實現這兩本字典的存儲和搜索的,因為這兩本字典的所有<key, value>條目均分布式地存儲在參與Kad網絡的各節(jié)點中,相關文件信息、下載位置信息的存儲和交換均無需集中索引服務器的參與,這不僅提高了查詢效率,而且還提高了整個P2P文件交換系統的可靠性,同時具備相當的反拒絕服務攻擊能力;更有意思的是,它能幫助我們有效地抵制FBI的追捕,因為俗話說得好:法不治眾…看到這里,相信大家都能理解“分布式信息檢索”所帶來的好處了吧。但是,這些條目究竟是怎樣存儲的呢?我們又該如何通過Kad網絡來找到它們?不著急,慢慢來。
4. 什么叫做節(jié)點的ID和節(jié)點之間的距離?
Kad網絡中的每一個節(jié)點均擁有一個專屬ID,該ID的具體形式與SHA1散列值類似,為一個長達160bit的整數,它是由節(jié)點自己隨機生成的,兩個節(jié)點擁有同一ID的可能性非常之小,因此可以認為這幾乎是不可能的。在Kad網絡中,兩個節(jié)點之間距離并不是依靠物理距離、路由器跳數來衡量的,事實上,Kad網絡將任意兩個節(jié)點之間的距離d定義為其二者ID值的逐比特二進制和數,即,假定兩個節(jié)點的ID分別為a與b,則有:d=a XOR b。在Kad中,每一個節(jié)點都可以根據這一距離概念來判斷其他節(jié)點距離自己的“遠近”,當d值大時,節(jié)點間距離較遠,而當d值小時,則兩個節(jié)點相距很近。這里的“遠近”和“距離”都只是一種邏輯上的度量描述而已;在Kad中,距離這一度量是無方向性的,也就是說a到b的距離恒等于b到a的距離,因為a XOR b==b XOR a
5. <key, value>條目是如何存儲在Kad網絡中的?
從上文中我們可以發(fā)現節(jié)點ID與<key, value>條目中key值的相似性:無論是關鍵詞字典的key,還是文件索引字典的key,都是160bit,而節(jié)點ID恰恰也是160bit。這顯然是有目的的。事實上,節(jié)點的ID值也就決定了哪些<key, value>條目可以存儲在該節(jié)點之中,因為我們完全可以把某一個<key, value>條目簡單地存放在節(jié)點ID值恰好等于條目中key值的那個節(jié)點處,我們可以將滿足(ID==key)這一條件的節(jié)點命名為目標節(jié)點N。這樣的話,一個查找<key, value>條目的問題便被簡單地轉化成為了一個查找ID等于Key值的節(jié)點的問題。
由于在實際的Kad網絡當中,并不能保證在任一時刻目標節(jié)點N均一定存在或者在線,因此Kad網絡規(guī)定:任一<key, value>條目,依據其key的具體取值,該條目將被復制并存放在節(jié)點ID距離key值最近(即當前距離目標節(jié)點N最近)的k個節(jié)點當中;之所以要將<key, value>重復保存k份,這完全是考慮到整個Kad系統穩(wěn)定性而引入的冗余;這個k的取值也有講究,它是一個帶有啟發(fā)性質的估計值,挑選其取值的準則為:“在當前規(guī)模的Kad網絡中任意選擇至少k個節(jié)點,令它們在任意時刻同時不在線的幾率幾乎為0”;目前,k的典型取值為20,即,為保證在任何時刻我們均能找到至少一份某<key, value>條目的拷貝,我們必須事先在Kad網絡中將該條目復制至少20份。
由上述可知,對于某一<key, value>條目,在Kad網絡中ID越靠近key的節(jié)點區(qū)域,該條目保存的份數就越多,存儲得也越集中;事實上,為了實現較短的查詢響應延遲,在條目查詢的過程中,任一條目可被cache到任意節(jié)點之上;同時為了防止過度cache、保證信息足夠新鮮,必須考慮<key, value>條目在節(jié)點上存儲的時效性:越接近目標結點N,該條目保存的時間將越長,反之,其超時時間就越短;保存在目標節(jié)點之上的條目最多能夠被保留24小時,如果在此期間該條目被其發(fā)布源重新發(fā)布的話,其保存時間還可以進一步延長。
6. Kad網絡節(jié)點需要維護哪些狀態(tài)信息?
在Kad網絡中,每一個節(jié)點均維護了160個list,其中的每個list均被稱之為一個k-桶(k-bucket),如下圖所示。在第i個list中,記錄了當前節(jié)點已知的與自身距離為2^i~2^(i+1)的一些其他對端節(jié)點的網絡信息(Node ID,IP地址,UDP端口),每一個list(k-桶)中最多存放k個對端節(jié)點信息,注意,此處的k與上文所提到的復制系數k含義是一致的;每一個list中的對端節(jié)點信息均按訪問時間排序,最早訪問的在list頭部,而最近新訪問的則放在list的尾部。
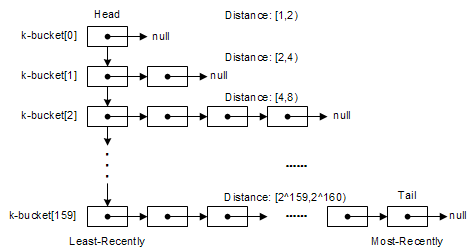 k-桶中節(jié)點信息的更新基本遵循Least-recently Seen Eviction原則:當list容量未滿(k-桶中節(jié)點個數未滿k個),且最新訪問的對端節(jié)點信息不在當前l(fā)ist中時,其信息將直接添入list隊尾,如果其信息已經在當前l(fā)ist中,則其將被移動至隊尾;在k-桶容量已滿的情況下,添加新節(jié)點的情況有點特殊,它將首先檢查最早訪問的隊首節(jié)點是否仍有響應,如果有,則隊首節(jié)點被移至隊尾,新訪問節(jié)點信息被拋棄,如果沒有,這才拋棄隊首節(jié)點,將最新訪問的節(jié)點信息插入隊尾。可以看出,盡可能重用已有節(jié)點信息、并且按時間排序是k-桶節(jié)點更新方式的主要特點。從啟發(fā)性的角度而言,這種方式具有一定的依據:在線時間長一點的節(jié)點更值得我們信任,因為它已經在線了若干小時,因此,它在下一個小時以內保持在線的可能性將比我們最新訪問的節(jié)點更大,或者更直觀點,我這里再給出一個更加人性化的解釋:MP3文件交換本身是一種觸犯版權法律的行為,某一個節(jié)點反正已經犯了若干個小時的法了,因此,它將比其他新加入的節(jié)點更不在乎再多犯一個小時的罪……-_-b
k-桶中節(jié)點信息的更新基本遵循Least-recently Seen Eviction原則:當list容量未滿(k-桶中節(jié)點個數未滿k個),且最新訪問的對端節(jié)點信息不在當前l(fā)ist中時,其信息將直接添入list隊尾,如果其信息已經在當前l(fā)ist中,則其將被移動至隊尾;在k-桶容量已滿的情況下,添加新節(jié)點的情況有點特殊,它將首先檢查最早訪問的隊首節(jié)點是否仍有響應,如果有,則隊首節(jié)點被移至隊尾,新訪問節(jié)點信息被拋棄,如果沒有,這才拋棄隊首節(jié)點,將最新訪問的節(jié)點信息插入隊尾。可以看出,盡可能重用已有節(jié)點信息、并且按時間排序是k-桶節(jié)點更新方式的主要特點。從啟發(fā)性的角度而言,這種方式具有一定的依據:在線時間長一點的節(jié)點更值得我們信任,因為它已經在線了若干小時,因此,它在下一個小時以內保持在線的可能性將比我們最新訪問的節(jié)點更大,或者更直觀點,我這里再給出一個更加人性化的解釋:MP3文件交換本身是一種觸犯版權法律的行為,某一個節(jié)點反正已經犯了若干個小時的法了,因此,它將比其他新加入的節(jié)點更不在乎再多犯一個小時的罪……-_-b
由上可見,設計采用這種多k-bucket數據結構的初衷主要有二:a. 維護最近-最新見到的節(jié)點信息更新;b. 實現快速的節(jié)點信息篩選操作,也就是說,只要知道某個需要查找的特定目標節(jié)點N的ID,我們便可以從當前節(jié)點的k-buckets結構中迅速地查出距離N最近的若干已知節(jié)點。
7. 在Kad網絡中如何尋找某特定的節(jié)點?
已知某節(jié)點ID,查找獲得當前Kad網絡中與之距離最短的k個節(jié)點所對應的網絡信息(Node ID,IP地址,UDP端口)的過程,即為Kad網絡中的一次節(jié)點查詢過程(Node Lookup)。注意,Kad之所以沒有把節(jié)點查詢過程嚴格地定義成為僅僅只查詢單個目標節(jié)點的過程,這主要是因為Kad網絡并沒有對節(jié)點的上線時間作出任何前提假設,因此在多數情況下我們并不能肯定需要查找的目標節(jié)點一定在線或存在。
整個節(jié)點查詢過程非常直接,其方式類似于DNS的迭代查詢:
a. 由查詢發(fā)起者從自己的k-桶中篩選出若干距離目標ID最近的節(jié)點,并向這些節(jié)點同時發(fā)送異步查詢請求;
b .被查詢節(jié)點收到請求之后,將從自己的k-桶中找出自己所知道的距離查詢目標ID最近的若干個節(jié)點,并返回給發(fā)起者;
c. 發(fā)起者在收到這些返回信息之后,再次從自己目前所有已知的距離目標較近的節(jié)點中挑選出若干沒有請求過的,并重復步驟1;
d. 上述步驟不斷重復,直至無法獲得比查詢者當前已知的k個節(jié)點更接近目標的活動節(jié)點為止。
e. 在查詢過程中,沒有及時響應的節(jié)點將立即被排除;查詢者必須保證最終獲得的k個最近節(jié)點都是活動的。
簡單總結一下上述過程,實際上它跟我們日常生活中去找某一個人打聽某件事是非常相似的,比方說你是個Agent Smith,想找小李(key)問問他的手機號碼(value),但你事先并不認識他,你首先肯定會去找你所認識的和小李在同一個公司工作的人,比方說小趙,然后小趙又會告訴你去找與和小李在同一部門的小劉,然后小劉又會進一步告訴你去找和小李在同一個項目組的小張,最后,你找到了小張,喲,正好小李出差去了(節(jié)點下線了),但小張恰好知道小李的號碼(cache),這樣你總算找到了所需的信息。在節(jié)點查找的過程中,“節(jié)點距離的遠近”實際上與上面例子中“人際關系的密切程度”所代表的含義是一樣的。
最后說說上述查詢過程的局限性:Kad網絡并不適合應用于模糊搜索,如通配符支持、部分查找等場合,但對于文件共享場合來說,基于關鍵詞的精確查找功能已經基本足夠了(值得注意的是,實際上我們只要對上述查找過程稍加改進,并可以令其支持基于關鍵詞匹配的布爾條件查詢,但仍不夠優(yōu)化)。這個問題反映到eMule的應用層面來,它直接說明了文件共享時其命名的重要性所在,即,文件名中的關鍵詞定義得越明顯,則該文件越容易被找到,從而越有利于其在P2P網絡中的傳播;而另一方面,在eMule中,每一個共享文件均可以擁有自己的相關注釋,而Comment的重要性還沒有被大家認識到:實際上,這個文件注釋中的關鍵詞也可以直接被利用來替代文件名關鍵詞,從而指導和方便用戶搜索,尤其是當文件名本身并沒有體現出關鍵詞的時候。
8. 在Kad網絡中如何存儲和搜索某特定的<key, value>條目?
從本質上而言,存儲、搜索某特定<key, value>條目的問題實際上就是節(jié)點查找的問題。當需要在Kad網絡中存儲一個條目時,可以首先通過節(jié)點查找算法找到距離key最近的k個節(jié)點,然后再通知它們保存<key, value>條目即可。而搜索條目的過程則與節(jié)點查詢過程也是基本類似,由搜索發(fā)起方以迭代方式不斷查詢距離key較近的節(jié)點,一旦查詢路徑中的任一節(jié)點返回了所需查找的value,整個搜索的過程就結束。為提高效率,當搜索成功之后,發(fā)起方可以選擇將搜索到的條目存儲到查詢路徑的多個節(jié)點中,作為方便后繼查詢的cache;條目cache的超時時間與節(jié)點-key之間的距離呈指數反比關系。
9. 一個新節(jié)點如何首次加入Kad網絡?
當一個新節(jié)點首次試圖加入Kad網絡時,它必須做三件事,其一,不管通過何種途徑,獲知一個已經加入Kad網絡的節(jié)點信息(我們可以稱之為節(jié)點I),并將其加入自己的k-buckets;其二,向該節(jié)點發(fā)起一次針對自己ID的節(jié)點查詢請求,從而通過節(jié)點I獲取一系列與自己距離鄰近的其他節(jié)點的信息;最后,刷新所有的k-bucket,保證自己所獲得的節(jié)點信息全部都是新鮮的。
參考文獻
1. Kademlia: A Peer-to-peer Information System Based on the XOR Metric, Petar Maymounkov, Proc. IPTPS 2002
2. 到底什么是Kad, http://bbs.5qzone.NET/read.php?tid=321431
3. Kademlia原理介紹, http://www.edonkey2000.cn/bbs/viewthread.php?tid=58238
it知識庫:eMule中的分布式哈希表技術: Kademlia,轉載需保留來源!
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播更多信息之目的,如作者信息標記有誤,請第一時間聯系我們修改或刪除,多謝。



