
|
|
英文原文:ASPects of Domain Model Management
(作者:Mats Helander,譯者:王麗娟)
2007-12-23
導言
正如從像《領域驅動設計》[Evans DDD]和《領域驅動設計和模式應用》[Nilsson ADDDP]這些書中學到的一樣,在應用架構中引入領域模型模式(《企業應用架構模式》[Fowler PoEAA])一定會有很多益處,但是它們并不是無代價的。
使用領域模型,很少會像創建實際領域模型類、然后使用它們那么簡單。很快你就會發現,領域模型必須得到相當數量的基礎架構代碼的支持。
領域模型所需基礎架構當中最顯著的當然是持久化——通常是持久化到關系型數據庫中,也就是對象/關系(O/R)映射出場的地方。但是,情況并不止持久化那么簡單。在一個復雜的應用中,用來在運行時管理領域模型對象的部分占了基礎架構的很大一部分。我將基礎架構的這部分稱為領域模型管理(Domain Model Management)[Helander DMM],或簡稱為DMM。
基礎架構代碼放在哪里?
隨著基礎架構代碼的增長,找到一個處理它的優良架構變得越來越重要。問題主要在于——我們是否允許把一些基礎架構代碼放在我們的領域模型類里面,還是無論如何應該避免這樣做?
避免基礎架構代碼進入領域模型類的論點是強有力的:領域模型應該表示應用程序所處理的核心業務概念。對于想大量使用其領域模型的應用來說,保持這些類干凈、輕量級、易于維護是一個極好的架構目標。
另一方面,我們接下來將會看到,保持領域模型類完全不含基礎架構代碼——通常被稱為使用POJO/POCO(Plain Old Java/CLR Objects)領域模型,這種極端的路線也被證明是有問題的。最終往往導致采用笨重的、低效率的變通方法來解決問題——而且有些功能用這種方式根本不可能實現。
也就是說,我們遇到的還是一個權衡利弊的情況,我們應該盡量在領域模型類里面只放必不可少的基礎架構代碼,決不超出這個限度。我們付出領域模型的輕微發胖,換來效率的提高以及使一些必要領域模型管理功能有可能實現。畢竟,軟件架構很大程度上是關于如何做一筆好買賣。
重構的時機到了
不幸的是,長遠看來,臺面上的交易條件可能不夠好。為了支持許多最有用和最強大的功能,你需要在領域模型類中放入基礎架構代碼實在太多了。其數量之大,很可能你的系統還沒完成,業務邏輯代碼就已經被淹沒了。
也就是說,除非我們能找到一種方法魚和熊掌兼得。本文試圖分析我們能否找到這樣一種方式,既能將必要的基礎架構代碼分布到領域模型中,卻又不會使領域模型類變得雜亂。
我們先從一個應用看起,它將所有有關的基礎架構代碼都放到了領域模型類中。接著我們將重構這個應用,并且只用眾所周知的、可靠的、真正面向對象的設計模式,使應用最后能具備相同的功能,但是基礎架構代碼卻不會弄亂領域模型類。最后,我們將看看我們如何使用面向方面編程(ASPect Oriented Programming,AOP)來更簡單地達到相同的效果。
但是,為了看出AOP為何能幫助我們處理DMM需求,我們首先看看沒有AOP的時候我們的代碼會是什么樣——首先是“最原始”的形式,這種形式里,所有的基礎架構代碼都放在領域模型類里面,然后是重構后的形式,其中基礎架構代碼已經被分離出領域模型類——雖然仍然分布在領域模型中!
重構肥領域模型
大部分的領域模型運行時管理是基于攔截的——也就是說,當你在代碼中訪問領域模型對象時,你所有對對象的訪問都會根據相應功能的需要被攔截下來。
一個明顯的例子就是臟跟蹤(dirty tracking)。它可以用于應用的很多部分,以了解一個對象什么時候已經被修改了、但是仍未保存(它處于“臟”狀態)。用戶界面可以利用該信息提醒用戶是否打算放棄任何未保存的修改,而持久化機制則可以利用它來辨明哪些對象是真正需要被保存到持久化介質中的,從而避免保存所有的對象。
臟跟蹤的一種方法是保持領域對象最初的、未修改版本的拷貝,并在每次想知道一個對象是否已經被修改的時候去比較它們。這個方案的問題是既浪費內存,又慢。一個更有效率的方法是攔截對領域對象setter方法的調用,以便每當調用對象的一個setter方法的時候,都為該對象設置一個臟標記。
臟標記放在哪里?
現在我們來看看把臟標記放在哪里的問題。一種是將它放在一個字典結構中,對象和標記分別作為鍵和值。這樣做的問題在于,我們必須讓程序中所有需要它的部分都能訪問到這個字典。前面的例子已經可以看出,需要訪問字典的包括用戶界面和持久化機制這樣截然不同的部分。
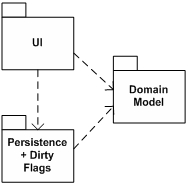
圖 1
將字典放在這些組件的任何一個內部,都會使其它組件難以訪問它。在分層結構中,底層不能調用其上層(除了中心領域模型,它常常處于一個公共的、垂直的層里面,能被其它所有的層調用),因此要么把字典放在需要訪問它的最低一層(圖1),要么放在公共的、垂直的層里面(圖2)。兩種選擇都不是很有吸引力,因為它引起了應用組件間不必要的耦合和不均衡的責任分配。
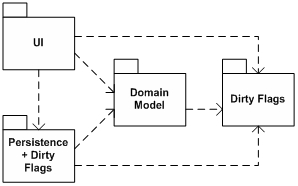
圖 2
一個更吸引人的、順應面向對象思想的選擇,是將臟標記放到領域對象本身中去,這樣每個領域對象都帶有一個布爾型的臟屬性,來表明它是不是臟的(圖3)。這樣,任何組件想知道一個領域對象臟與否,可以直接問它。
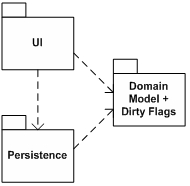
圖 3
因此,我們把部分基礎架構功能代碼放在領域模型中,其部分原因就是我們希望從應用的不同部分都能擁有這些功能,而不會過度地增強耦合。用戶界面部分不該知道如何向持久化組件詢問臟標志,并且,我們寧愿在分層的應用架構中設計盡可能少的垂直層。
這個理由很重要,單憑它就足以讓一些人考慮采納本文將要檢驗的這種方法,不過我們還是先看看其他方法。但是在這樣做之前,我們先粗略地看一下爭論的另一方——我們在領域模型類中限制基礎架構代碼的原因。
肥領域模型反模式
讓我們看看,引入臟標記、并在適當時機要求攔截喚醒臟標記之后,領域類會是什么樣子。這是一個C#代碼的例子。
public class Person : IDirty
{
protected string name;
public virtual string Name
{
get { return name; }
set
{
if (value != name)
((IDirty)this).Dirty = true;
name = value;
}
}
private bool dirty;
bool IDirty.Dirty
{
get { return dirty; }
set { dirty = value; }
}
}
public interface IDirty
{
bool Dirty { get; set; }
}
it知識庫:領域模型管理與AOP,轉載需保留來源!
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播更多信息之目的,如作者信息標記有誤,請第一時間聯系我們修改或刪除,多謝。



