|
|
“內存是新的硬盤,硬盤是新的磁帶”此話出自圖靈獎得主Jim Gray。
一、前言
我理解這句話的意思是,我們應該把隨機IO都放到內存中去,而把像磁帶一樣的順序IO留給硬盤(這里不包括SSD)。
如果應用沒有達到一定的級別,可能我們看上面兩句話都會覺得太geek,然而在應用數據量日益龐大,動態內容比例日益增大的今天,再忽視這個基本準則將會是一個災難。
今天我們談一下這一理論在NoSQL產品中的展現。
二、實現
問題一:宕機數據丟失
我們先看一下幾個杰出的NoSQL代表,Cassandra,MongoDB,Redis。他們幾乎都使用了同一種存儲模式,就是將寫操作在內存中進行,定時或按某一條件將內存中的數據直接寫到磁盤上。這樣做的好處是我們可以充分利用內存在隨機IO上的優勢,而避免了直接寫磁盤帶來的隨機IO瓶頸:磁盤尋道時間。當然,壞處就是如果遭遇宕機等問題時,可能會丟失一些數據。
解決宕機丟數據的問題有兩個方法:
1.實時記錄操作日志
這時通常的做法是當一個寫操作到達,系統首先會往日志文件里追加一條寫記錄,成功后再操作內存進行寫數據操作。而由于日志文件是不斷追加的,因此也就保證了不會有大量的隨機IO產生。
2.Quorum NRW
這一理論是基于集群式存儲的,其原理是如果集群有N個結點,那么如果我們每次寫操作需要至少同步到W個結點才算成功,而每次讀操作只要從R個結點讀數據就一定能保證其得到正確結果(如果某一結點有此數據,既成功,如果所有R個結點都無數據,則說明無此數據)。而NRW之間的關系必須滿足N < R + W 。其實這一理論并不難理解,我們可以將這個不等式做一下移項:R > N – W ,我們有N個結點,寫的時候最少寫W個才算成功,也就是W個結點有這份數據,那么N-W就是說可能沒有某一份數據的最大結點數。最多可能有N-W個結點沒有某一數據,那如果我們進行數據讀取操作時,讀到大于N-W個結點,那么必然有一個以上的結點是有這份數據的。所以要求R > N – W。
所以可能你已經想明白了,為了防止數據丟失,我們采用的實際是簡單的冗余備份的方法。數據寫到多臺機器會比寫單臺機器的磁盤快嗎?對。相對于直接的磁盤操作,跨網絡進行內存操作可以更快。其最簡單的例子就是改進的一致性hash,(關于一致性hash請看這里):
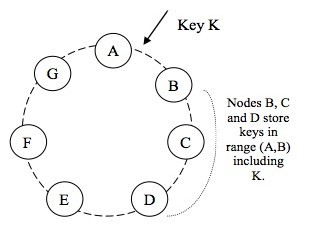
上圖摘自Amazon的Dynamo文檔,key的hash值位于A,B結點間的數據,并不是只存在B結點上,而是順著環的方向分別在C和D結點進行備份。當然這樣做的好處并不完全在于上面說的冗余備份。
當然,很多時候是上面兩種解決方法同時使用以保證數據的高可用性。
問題二:內存容量的限制
當我們將內存當作硬盤來用的時候,我們必然會面臨容量問題。這也是我們上面說到的數據會定時flush到磁盤的原因,當內存中的數據已經超出可用內存的大小,那么我們就需要將其進行落地操作,對swap的過度使用是不符合我們初衷的,也是達不到高效隨機IO的效果的。這里也有兩種解決方案:
1.應用層swap
采用這種方法的有 TokyoCabiNET 和 Redis 兩個產品。TokyoCabiNET主要是通過mmap提高IO效率,而其mmap到的只有數據文件頭部的一部分內容。一旦數據文件大于其設置的最大mmap長度(由參數xmsize控制),那剩下的部分就是純粹的低效磁盤操作了。于是它提供了一種類似于Memcached的緩存機制,通過參數rcnum配置,將一些通過LRU機制篩選出來的熱數據進行key-value式的緩存,這一部分內存是和mmap占用的內存完全獨立的。同樣的,Redis在2.0版本之后增加了對磁盤存儲的支持,其機制與 TokyoCabiNET 類似,也是通過數據操作來判斷數據的熱度,并將熱數據盡量放到內存中。
2.多版本的數據合并
什么叫多版本的數據合并呢?我們上面講 Bigtable,或其開源版本 Cassandra,都是通過定時將內存中的數據塊flush到磁盤中,那么我們會想,如果這次是一個update操作,比如 keyA 的值從 ValueA 變成了 ValueB,那么我們在flush到磁盤的時候就得執行對老數據 ValueA 的清除工作了。而這樣,是否就達不到我們希望進行順序的磁盤IO的目的呢?沒錯,這樣是達不到的,所以 Bigtable 類型的系統確實也并不是這樣做的,在flush磁盤的時候,并不會執行合并操作,而是直接將內存數據寫入磁盤。這樣寫是方便很多,那讀的時候可能會存在一個值有多個版本的情況,這時就需要我們來進行多版本合并了。所以第二種方法就是將一段時間的寫操作寫成一個塊(可能并非一個文件),保證內存的使用不會無限膨脹。在讀取時通過讀多個文件塊進行數據版本合并來完成。
那如果存儲在磁盤的數據量是內存容量的很多倍,我們可能會產生許多個數據塊,那么我們在獲取數據版本時,是否需要全部遍歷所有數據塊呢?當然不用,如果你看過BigTable論文,相信你還記得它其中用到了 bloom-filter 算法。bloom-filter 算法最廣泛的應用是在搜索引擎爬蟲中,它用于判斷一個URL是否存在于已抓取集合中,這一算法并不百分之百精準(可能將不在集合中的數據誤判為在集合中,但不會出現相反的誤差),但其在時間復雜度上僅是幾次hash計算,而空間復雜度也非常低。Bigtable 實現中也用到了 bloom-filter 算法,用它來判斷一個值是否在某一個集合中。而由于 bloom-filter 算法的特點,我們只會多讀(幾率很小),不會少讀數據塊。于是我們就實現對遠遠大于物理內存容量的數據的存儲。
三、結尾
好了,就寫到這里,關于NoSQL中對此原理的應用還有更多理解和認識的同學,歡迎交流。
it知識庫:NoSQL理論之-內存是新的硬盤,硬盤是新的磁帶,轉載需保留來源!
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播更多信息之目的,如作者信息標記有誤,請第一時間聯系我們修改或刪除,多謝。



