|
|
引言:數(shù)據(jù)庫(kù)設(shè)計(jì) Step by Step (1)得到這么多朋友的關(guān)注著實(shí)出乎了我的意外。這也堅(jiān)定了我把這一系列的博文寫好的決心。近來(lái)工作上的事務(wù)比較繁重,加之我期望這個(gè)系列的文章能盡可能的系統(tǒng)、完整,需要花很多時(shí)間整理、思考數(shù)據(jù)庫(kù)設(shè)計(jì)的各種資料,所以文章的更新速度可能會(huì)慢一些,也希望大家能夠諒解。
系列的第二講我們將站在高處俯瞰一下數(shù)據(jù)庫(kù)的生命周期,了解數(shù)據(jù)庫(kù)設(shè)計(jì)的整體流程。
 數(shù)據(jù)庫(kù)生命周期
數(shù)據(jù)庫(kù)生命周期
大家對(duì)軟件生命周期較為熟悉,數(shù)據(jù)庫(kù)也有其生命周期,如下圖所示。
 圖(1)數(shù)據(jù)庫(kù)生命周期
圖(1)數(shù)據(jù)庫(kù)生命周期
數(shù)據(jù)庫(kù)的生命周期主要分為四個(gè)階段:需求分析、邏輯設(shè)計(jì)、物理設(shè)計(jì)、實(shí)現(xiàn)維護(hù)。
這個(gè)系列的博文將主要關(guān)注數(shù)據(jù)庫(kù)生命周期中的前兩個(gè)階段(需求分析、邏輯設(shè)計(jì)),還會(huì)涉及反范式化設(shè)計(jì)的一些內(nèi)容。如圖中高亮圈出的部分。
數(shù)據(jù)庫(kù)的物理設(shè)計(jì),包括索引的選擇與優(yōu)化、數(shù)據(jù)分區(qū)等內(nèi)容。這些內(nèi)容也非常豐富,而且可以自成體系,園子里也有很多好文章,故在本系列中不作主要關(guān)注。本文最后將給出一些鏈接供大家參考。
數(shù)據(jù)庫(kù)生命周期的四個(gè)階段又能細(xì)分為多個(gè)小步驟,我們配合圖(1)來(lái)看看每一小步包含的內(nèi)容。
階段1 需求分析
數(shù)據(jù)庫(kù)設(shè)計(jì)與軟件設(shè)計(jì)一樣首先需要進(jìn)行需求分析。
我們需要與數(shù)據(jù)的創(chuàng)造者和使用者進(jìn)行訪談。對(duì)訪談獲得的信息進(jìn)行整理、分析,并撰寫正式的需求文檔。
需求文檔中需包含:需要處理的數(shù)據(jù);數(shù)據(jù)的自然關(guān)系;數(shù)據(jù)庫(kù)實(shí)現(xiàn)的硬件環(huán)境、軟件平臺(tái)等;
 圖(2)階段1 需求分析
圖(2)階段1 需求分析
階段2 邏輯設(shè)計(jì)
使用ER或UML建模技術(shù),創(chuàng)建概念數(shù)據(jù)模型圖,展示所有數(shù)據(jù)以及數(shù)據(jù)間關(guān)系。最終概念數(shù)據(jù)模型必須被轉(zhuǎn)化為范式化的表。
數(shù)據(jù)庫(kù)邏輯設(shè)計(jì)主要步驟包括:
a) 概念數(shù)據(jù)建模
在需求分析完成后,使用ER圖或UML圖對(duì)數(shù)據(jù)進(jìn)行建模。使用ER圖或UML圖描述需求中的語(yǔ)義,即得到了數(shù)據(jù)概念模型(Conceptual Data Model),例如:三元關(guān)系(ternary relationships)、超類(supertypes)、子類(subtypes)等。
eg: 零售商視角,產(chǎn)品/客戶數(shù)據(jù)庫(kù)的ER模型簡(jiǎn)圖
注:ER圖的含義,以及詳細(xì)標(biāo)記方法將在該系列的下一篇博文中進(jìn)行討論
圖(3)階段2(a) 概念數(shù)據(jù)建模
b) 多視圖集成
當(dāng)在大型項(xiàng)目設(shè)計(jì)或多人參與設(shè)計(jì)的情況下,會(huì)產(chǎn)生數(shù)據(jù)和關(guān)系的多個(gè)視圖。這些視圖必須進(jìn)行化簡(jiǎn)與集成,消除模型中的冗余與不一致,最終形成一個(gè)全局的模型。多視圖集成可以使用ER建模語(yǔ)義中的同義詞(synonyms)、聚合(aggregation)、泛化(generalization)等方法。多視圖集成在整合多個(gè)應(yīng)用的場(chǎng)景中也非常重要。
eg: 集成零售商ER圖與客戶ER圖
零售商ER圖如圖(3)所示。客戶視角,產(chǎn)品/客戶數(shù)據(jù)庫(kù)的ER模型簡(jiǎn)圖如下:
圖(4)以客戶為關(guān)注點(diǎn)繪制的ER圖
注:現(xiàn)在市面上有許多輔助建模工具可以繪制ER圖。使用Sybase的PowerDesigner繪制與圖(4)相同語(yǔ)義的ER圖如下:
其標(biāo)記法與圖(4)中略有不同,這將在今后的博文中加以說(shuō)明。
這里需要指出的是輔助軟件的使用不是設(shè)計(jì)的核心,大家不要被這些工具迷惑。所以后文中我們將主要使用手繪。只要掌握了ER圖的語(yǔ)義,使用這些軟件都不會(huì)是件難事。
集成零售商ER圖與客戶ER圖
圖(5) 階段2(b) 多視圖集成

c) 轉(zhuǎn)化概念數(shù)據(jù)模型為SQL表
根據(jù)映射規(guī)則,把ER圖中的實(shí)體與關(guān)系轉(zhuǎn)化為SQL表結(jié)構(gòu)。在這一過(guò)程中我們將識(shí)別冗余的表,并去除這些表。
eg: 把圖(5)中的customer, product, salesperson實(shí)體轉(zhuǎn)化為SQL表
圖(6) 階段2(c)轉(zhuǎn)化概念數(shù)據(jù)模型為SQL表
d) 范式化
范式化是數(shù)據(jù)庫(kù)邏輯設(shè)計(jì)中的重要一步。范式化的目標(biāo)是盡可能去除模型中的冗余信息,從而消除關(guān)系模型更新、插入、刪除異常(anomalies)。
講到范式化就會(huì)引出函數(shù)依賴(Functional Dependency)這一概念。函數(shù)依賴(FDs)源自于概念數(shù)據(jù)模型圖,反映了需求分析中的數(shù)據(jù)關(guān)系語(yǔ)義。不同實(shí)體之間的函數(shù)依賴表示各個(gè)實(shí)體唯一鍵之間的依賴。實(shí)體內(nèi)部也有函數(shù)依賴,反映了實(shí)體中鍵屬性與非鍵屬性之間的依賴。在保證數(shù)據(jù)完整性約束的前提下,基于函數(shù)依賴對(duì)候選表進(jìn)行范式化(分解、降低數(shù)據(jù)冗余)。
eg: 對(duì)圖(6)中的Salesperson表進(jìn)行范式化,消除更新異常(update anomalies)
圖(7) 階段2(d)范式化
階段3 物理設(shè)計(jì)
數(shù)據(jù)庫(kù)物理設(shè)計(jì)包括選擇索引,數(shù)據(jù)分區(qū)與分組等。
邏輯設(shè)計(jì)方法學(xué)通過(guò)減少需要分析的數(shù)據(jù)依賴,簡(jiǎn)化了大型關(guān)系數(shù)據(jù)庫(kù)的設(shè)計(jì),這也減輕了數(shù)據(jù)庫(kù)物理設(shè)計(jì)階段的壓力。
1. 概念數(shù)據(jù)建模和多視圖集成準(zhǔn)確地反映了現(xiàn)實(shí)需求場(chǎng)景
2. 范式化在模型轉(zhuǎn)化為SQL表的過(guò)程中保留了數(shù)據(jù)完整性
數(shù)據(jù)庫(kù)物理設(shè)計(jì)的目標(biāo)是盡可能優(yōu)化性能。
物理設(shè)計(jì)階段,全局表結(jié)構(gòu)可能需要進(jìn)行重構(gòu)來(lái)滿足性能上的需求,這被稱為反范式化。
反范式化的步驟包括:
1. 辨別關(guān)鍵性流程,如頻繁運(yùn)行、大容量、高優(yōu)先級(jí)的處理操作
2. 通過(guò)增加冗余來(lái)提高關(guān)鍵性流程的性能
3. 評(píng)估所造成的代價(jià)(對(duì)查詢、修改、存儲(chǔ)的影響)和可能損失的數(shù)據(jù)一致性
階段4 數(shù)據(jù)庫(kù)的實(shí)現(xiàn)維護(hù)
當(dāng)設(shè)計(jì)完成之后,使用數(shù)據(jù)庫(kù)管理系統(tǒng)(DBMS)中的數(shù)據(jù)定義語(yǔ)言(DDL)來(lái)創(chuàng)建數(shù)據(jù)結(jié)構(gòu)。
數(shù)據(jù)庫(kù)創(chuàng)建完成后,應(yīng)用程序或用戶可以使用數(shù)據(jù)操作語(yǔ)言(DML)來(lái)使用(查詢、修改等)該數(shù)據(jù)庫(kù)。
一旦數(shù)據(jù)庫(kù)開(kāi)始運(yùn)行,就需要對(duì)其性能進(jìn)行監(jiān)視。當(dāng)數(shù)據(jù)庫(kù)性能無(wú)法滿足要求或用戶提出新的功能需求時(shí),就需要對(duì)該數(shù)據(jù)庫(kù)進(jìn)行再設(shè)計(jì)與修改。這形成了一個(gè)循環(huán):監(jiān)視 –> 再設(shè)計(jì) –> 修改 –> 監(jiān)視…。
 在進(jìn)行數(shù)據(jù)庫(kù)設(shè)計(jì)之前,我們先回顧一下關(guān)系數(shù)據(jù)庫(kù)的相關(guān)基本概念。
在進(jìn)行數(shù)據(jù)庫(kù)設(shè)計(jì)之前,我們先回顧一下關(guān)系數(shù)據(jù)庫(kù)的相關(guān)基本概念。
這里只做一個(gè)提綱挈領(lǐng)的簡(jiǎn)介,大家可以根據(jù)相應(yīng)的線索進(jìn)行擴(kuò)展。
表、行、列
關(guān)系數(shù)據(jù)庫(kù)可以想象成表的集合,每個(gè)表包含行與列。(可以想象成一個(gè)Excel workbook,包含多個(gè)worksheet)。
表在關(guān)系代數(shù)中被稱為關(guān)系,這也是關(guān)系數(shù)據(jù)庫(kù)名稱的起源(不要與表之間的外鍵關(guān)系混淆)。
列在關(guān)系代數(shù)中被稱為屬性(attribute)。列中允許存放的值的集合稱為列的域(域與數(shù)據(jù)類型密切相關(guān),但并不完全相同)。
行在關(guān)系代數(shù)中的學(xué)名是元組(tuple)。
關(guān)系數(shù)據(jù)庫(kù)的理論基礎(chǔ)來(lái)自于“關(guān)系代數(shù)”。但在關(guān)系代數(shù)中,一個(gè)集合的各個(gè)元組沒(méi)有次序的概念,在關(guān)系數(shù)據(jù)庫(kù)中為了方便使用,定義了行的次序。
鍵、索引
鍵是一種約束,目的是保證數(shù)據(jù)完整性
1. 復(fù)合鍵(Compound key):由多個(gè)數(shù)據(jù)列組成的鍵
2. 超鍵(Superkey):列的集合,其中任何兩行都不會(huì)完全相同
3. 候選鍵(Candidate key):首先是一個(gè)超鍵,同時(shí)這個(gè)超鍵中的任何列的缺失都會(huì)破壞行的唯一性
4. 主鍵(Primary key):指定的某個(gè)候選鍵
索引是數(shù)據(jù)的物理組織形式,目的是提高查詢的性能
約束
基本約束
not null constraint, domain constraint
檢查約束(Check Constraints)
eg: Salary > 0
主鍵約束(Primary Key Constraints)
實(shí)體完整性(entity integrity),沒(méi)有兩條記錄是完全相同的,組成主鍵的字段不能為null
唯一性約束(Unique Constraints)
外鍵約束(Foreign Key Constraints)
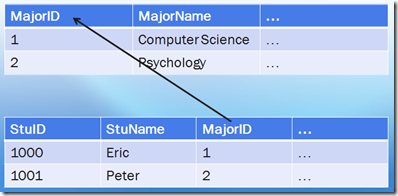
關(guān)系數(shù)據(jù)庫(kù)操作
1.選擇(Selection)
2.映射(Projection)
3.聯(lián)合(Union)
4.交集(Intersection)
5.差集(Difference)
6.笛卡爾積(Cartesian Product)
7.連接(Join)
上述7種是最基本的關(guān)系數(shù)據(jù)庫(kù)操作,對(duì)應(yīng)于集合論中的關(guān)系運(yùn)算。
有些書(shū)籍中還會(huì)加入改名(Rename),除(Divide)等關(guān)系操作。
 主要內(nèi)容回顧
主要內(nèi)容回顧
1. 數(shù)據(jù)庫(kù)生命周期的四個(gè)階段:需求分析、邏輯設(shè)計(jì)、物理設(shè)計(jì)、實(shí)現(xiàn)維護(hù)。
2. 關(guān)系數(shù)據(jù)庫(kù)的理論基礎(chǔ)是關(guān)系代數(shù)。
數(shù)據(jù)庫(kù)物理設(shè)計(jì)參考資料
第一個(gè)鏈接是我針對(duì)查詢優(yōu)化作的讀書(shū)筆記,后三個(gè)鏈接是SQLServerCentral中幾篇關(guān)于索引的文章(需要簡(jiǎn)單注冊(cè)后才能看到全文)
1. 查詢優(yōu)化系列(查詢優(yōu)化(1),查詢優(yōu)化(2),查詢優(yōu)化(3),查詢優(yōu)化(4),查詢優(yōu)化(5)——總結(jié))
2. Part 1 - The basics of indexes
3. Part 2 - The Clustered Index
4. Part 3 - The Non-clustered index
it知識(shí)庫(kù):數(shù)據(jù)庫(kù)設(shè)計(jì) Step by Step (2),轉(zhuǎn)載需保留來(lái)源!
鄭重聲明:本文版權(quán)歸原作者所有,轉(zhuǎn)載文章僅為傳播更多信息之目的,如作者信息標(biāo)記有誤,請(qǐng)第一時(shí)間聯(lián)系我們修改或刪除,多謝。



