|
|
一、理解索引的結(jié)構(gòu)
索引在數(shù)據(jù)庫中的作用類似于目錄在書籍中的作用,用來提高查找信息的速度。使用索引查找數(shù)據(jù),無需對整表進(jìn)行掃描,可以快速找到所需數(shù)據(jù)。微軟的SQL SERVER提供了兩種索引:聚集索引(clustered index,也稱聚類索引、簇集索引)和非聚集索引(nonclustered index,也稱非聚類索引、非簇集索引)。
SQL Server 中數(shù)據(jù)存儲的基本單位是頁(Page)。數(shù)據(jù)庫中的數(shù)據(jù)文件(.mdf 或 .ndf)分配的磁盤空間可以從邏輯上劃分成頁(從 0 到 n 連續(xù)編號)。磁盤 I/O 操作在頁級執(zhí)行。也就是說,SQL Server 每次讀取或?qū)懭霐?shù)據(jù)的最少數(shù)據(jù)單位是數(shù)據(jù)頁。
下面我們先簡單的了解一下索引的體系結(jié)構(gòu):
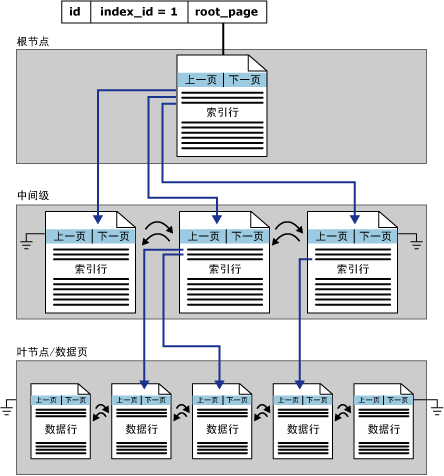
1. 聚集索引結(jié)構(gòu)
在 SQL Server 中,索引是按 B 樹結(jié)構(gòu)進(jìn)行組織的。
聚集索引單個分區(qū)中的結(jié)構(gòu):
--建立UserAddDate聚集索引CREATE CLUSTERED INDEX [IX_AddDate] ON [User]( [AddDate] ASC)
it知識庫:數(shù)據(jù)庫索引的基礎(chǔ)知識,轉(zhuǎn)載需保留來源!
鄭重聲明:本文版權(quán)歸原作者所有,轉(zhuǎn)載文章僅為傳播更多信息之目的,如作者信息標(biāo)記有誤,請第一時間聯(lián)系我們修改或刪除,多謝。



