|
|
背景
在看阿凡達的時候,感嘆著他們接口的統一,和獲取知識的便利性。有時候在想,現在很多企業所做的工作,不就是要提供這類服務嗎。設想一下,我們有一朵公有云,存儲了用戶的數據、邏輯關系,提供標準的通訊接口,然后大家各自開發豐富的展現邏輯,讓云端變的豐富多彩。這次很榮幸能接到這個議題,談談我個人對這朵云的理解。
每個人心中都有自己的一朵云,在我設想中,應該存在這么一種公有服務,它能夠幫助用戶隨時隨地的獲取自己的數據,與朋友交流,獲取好友最新狀態。在這服務之上,我們有這么一個平臺,它能夠給用戶提供二次開發的接口,讓開發者根據用戶數據開發豐富的展現層,并且提供這些展現層的運行平臺。
我們需要的云端服務
為了完成這個功能,我們需要什么準備?
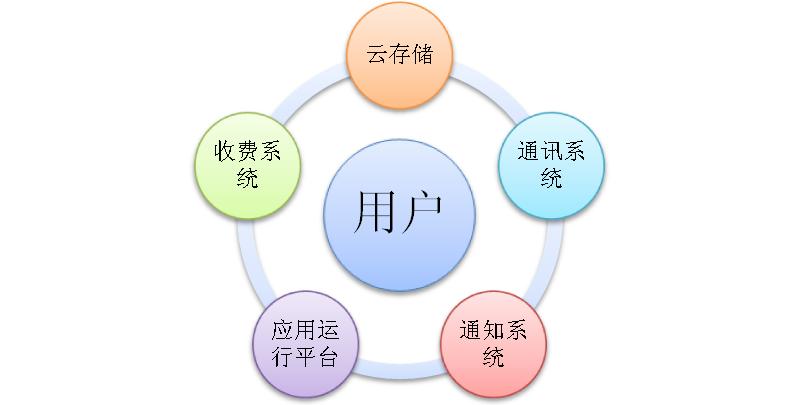
云存儲:提供用戶數據的存儲功能。讓用戶方便的獲取自己的數據。
通訊系統:提供以Mail,IM為基礎的通訊方式。
通知系統:好友行為推送,能夠把握好友最新動態,或者告知好友你在干什么。
在這三個基本服務之上,用戶可以開發大量的運用。比如“音樂盒”用于在線播放云存儲的MP3,圖片系統用于管理、分享,美化自己的照片……然而,用戶開發完邏輯應用之后,需要機器運行這個運用。因此,第四個基本服務運行平臺孕育而生,它提供所有云應用運行的基本資源,包括內存、CPU、操作系統等。
這四個基本要素構建成一個面向終端用戶的操作系統平臺(也就是我們的云),它能夠隨時被訪問,通過瀏覽器或者手機的App。滿足用戶在任意時刻團購,玩三國殺,看視頻,聽音樂等需求。為了方便開發者開發更多的應用,我們抽象一種編程模式,提供豐富的SDK,加速應用的開發。由于云端服務,有很大一部分會被手機等嵌入式設備訪問,于是需要各種平臺的編程框架(Android、ios)。編程框架將更加關心業務邏輯,屏蔽分布式細節和運維問題。
在滿足這些開發便利性的前提下,為鼓勵用戶開發,提高APP質量和數目,需要一套良好的收費系統,幫助開發者更好的盈利。
圍繞這這朵云,一點點的展開,發現想說的東西太多,今天我們就談談其中的兩個核心架構:云端存儲和應用運行平臺(App Engine)。為什么要選這兩個?因為云的核心就是存儲和計算,其它都構建在存儲和計算之上的基礎服務和用戶運用。
云端存儲架構
云端存儲主要是為了存儲用戶數據,方便用戶訪問。它涉及了三方面的技術:
- 底層架構。包括:分布式存儲、文件目錄管理、用戶權限系統。
- 下載優化:各地CDN支持、客戶端下載技術(P2P)。
- 數據訪問前端優化
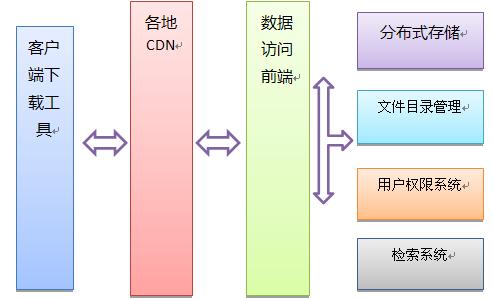
底層架構設計的要點
首先我們比較一下跟傳統離線存儲的設計指標差異
- 單個文件體積不大
- 文件數會很多
- 需要目錄管理
- 讀寫模式特殊性
- 檢索和訪問的實時性
存儲互聯網用戶的數據,注定文件不會很大。我們只要支持0-100G左右的單文件大小即可。為什么用戶文件會到100G?因為我們要保證用戶能分享高清電影。另外相對于海量的容量,如果單文件過小,那么海量空間也沒啥意義。多媒體是促進磁盤發展的動力。
跟GFS不一樣,云存儲的文件數是海量的。因為每個人都會存儲他們的文檔、mp3、圖片……這注定了單機保存全部文件的node是不可能的。
我們需要呈現傳統操作系統類似的目錄管理方式。另外根據云存儲文件數量多的特點,我們要提供可靠的檢索做文件管理。
用戶對文件的訪問模式是一次寫入,多次讀取,讀取支持隨機位置的讀取(比如視頻從中間開始播放)等。另外考慮在用戶帶寬條件下,100M的文件也算是大文件了,我們要需要支持斷點續傳功能。另外,存在對單文件的高并發訪問。
用戶上傳的數據,在上傳成功之后,就應該能訪問到完整的數據。并且在檢索的時候就能夠體現出來。因此不僅要求存儲系統要求實時性,而且檢索系統也有要求實時性。
歸納一下,因為文件太小導致文件數過多,需要專門的目錄存儲;針對文件的訪問模式,我們需要設計一個比較合理的文件格式;提升檢索的實時性。
文件格式介紹
一個文件需要的存儲數據:Meta信息和數據塊。Meta信息存儲這個文件的詳細信息,包括文件名、大小、文件類型(doc或者mp3)、MD5、創建者、具體數據塊的存放位置、數據塊大小,以及該文件格式的版本信息等。數據塊是真正存儲的文件數據。
我們將一個完整的文件,物理切成多塊。比如一個1G的文件,我們按照1M為塊大小,切成1024塊,然后將1024個塊數據散列到N臺機器中去。從而保證文件具備高并發的特點,而且也能夠方便的為整個集群提供擴展能力。然后我們會將這1024個塊的具體位置記錄到文件的meta信息中,方便訪問。
因此,我們需要一個邏輯文件的訪問入口(WebServer),和存儲這些數據塊與Meta信息的集群Chunk Cluster和Meta Cluster。

將一個不大的文件分散到各臺機器上存儲有什么好處?
- 方便做負載均衡和集群擴容
- 將熱門文件的流量分散到各臺機器上,使熱門文件的高頻訪問對后端影響降低。
這個文件格式的設計,大家可能會覺得文件很大的話,Meta信息因需要存儲的塊位置而導致體積過大。其實這個問題,可以通過二級索引塊來解決。
存儲架構的工作原理
如上圖,WebServer在接收Http請求的時候,會解析參數,然后根據Meta Cluster提供的Meta信息,讀取相關塊,返回給請求者。Chunck Cluster和Meta Cluster的設計都是一樣的,就是提供一套NoSQL系統,支持針對Key(字符串) - value(二進制)的增刪改查。但是考慮到訪問頻率的不同,我們需要針對不同的硬件做單機的優化,比如廉價的Sata盤存放相對靜止的數據,SSD盤存放訪問頻率過高的數據。
NoSQL集群不是我們這篇文件要簡述的話題,有機會可以詳談。不過即使是分布式系統,我們也應注重模塊的單機性能。因為如果我們的模塊單機性能提高一倍,那么我們的集群規模就會下降一倍。在上萬臺機器中,節約的成本是非常可觀的。我們如何衡量這個存儲系統的單機引擎性能呢?方法很簡單,如果一個單機模塊,能夠將網卡吞吐跑滿或者磁盤順序讀寫吞吐跑滿,對于存儲模塊本身來說,可以了。
目錄管理系統實現
海量文件的目錄管理,很難。這里,我們采用一個分布式有序表的方式來解決,分布式有序表也是NoSQL的一種。它對存儲的數據,提供基于字典序的游標查詢。比如:我們將所有的用戶文件名放入有序表中,該系統就會產生根據文件名排序的分布式數組,如下:
[/a.doc; /a/a.doc; /a/b.doc; /a/c.doc; /b.doc; /b/b/b.doc]
在執行ls /a/命令的時候,我們會尋找/a/的游標得到/a/a.doc,接著我們開始遍歷這個游標,直到不是/a/打頭為止。如果該過程中碰到子目錄,程序會會通過二分查找直接跳過子目錄,從而防止遍歷過多。如果數目過多,我們會展現100條,其它隱藏。目錄管理,主要是給用戶組織自己數據的時候用的,理論上,用戶不會在一個目錄下放太多的文件,即使太多,也沒關系,我們就顯示100條,然后提供下一頁的按鈕(因為下一頁的游標位置我們是知道的)。
實時檢索系統
討論這個議題的時候,需要假設我們已經有一個傳統的檢索系統,然后想辦法提高檢索的實時性。我們設計一個內存索引,把用戶新增的文件,對文件名切詞后放到內存中檢索,檢索的結果參與最終的合并。每隔五分鐘merge到傳統檢索系統中,然后釋放內存。云存儲,不像互聯網網頁,在5分鐘之內,僅文件名的索引,數據量不可能太大,所以內存不會是瓶頸。進一步的,我們可以對文件的內容作檢索,但是文件內容沒有必要做到實時。
權限系統
用戶權限系統,對于云存儲來說,也是個用戶文件,所以沒什么特別的,只不過我們需要專門的緩存做訪問優化。因為每一次讀寫請求,都要判斷訪問者是否有相關的權限。
CDN技術
P2P技術和CDN支持,主要是為了減少帶寬成本而做的,在云存儲這種數據量巨大的服務中,這兩種技術,顯的尤為重要。這兩塊是兩個專題,我們在這里不多做介紹。不過這兩個技術在解決熱點問題效果比較好,但是海量文件并不是所有文件都放CDN的,因此有些工作,數據訪問前端不得不做。
數據訪問與客戶端優化考慮
客戶端訪問速度差別,是我們要考慮的問題。如果是內部的訪問,帶寬可以保證是1000M以上,但是面向互聯網用戶,各種各樣的帶寬需求都有,比如GPRS、3G、ADSL,從20k-16M不等。這就要求我們的前端技術,在處理這些請求下要工作的很好。另外我們還要考慮在正常服務下,網絡帶寬最小化,比如一個視頻是100分鐘,我們就應該保證100分鐘內傳完,滿足正常播放,不能太快,因為太快,你不能保證用戶有耐心看完,可能他就看10分鐘,然后就關了,于是后面傳輸的帶寬全浪費了。如果是用戶下載,那么當然是越快越好。這些控制,我們都通過WebServer來實現。
WebServer最主要的功能就是高并發支持,限速。再加上云存儲的數據是海量的,傳統的Apache做WebServer肯定不適合,這里我們采用異步的WebSever比如lighttpd或者nginx,然后對客戶端句柄進行速度控制。為了支持大文件的斷點上傳,我們需要有一個專門的客服端,能夠將文件分塊上傳。Webserver必須支持根據md5查詢這個文件哪些塊已經上傳了,哪些沒上傳,從而通知客戶端正常工作。
云存儲有很多節約帶寬的優化,比如上傳文件的時候,先上傳md5,如果云端已經存在,就不需要上傳了,這樣可以做到大文件的秒傳,節約網絡帶寬。另外它提供對外標準的Http協議,可以采用迅雷等p2p軟件下載,從而提高訪問速度,減少服務器帶寬沖擊。為了數據安全性,我們還得提供https協議的數據訪問。
App Engine
完成云存儲的設計之后,我們需要一個開發平臺,這個開發平臺提供用戶邏輯的運行環境。這環境包括
- MYSQL集群化管理
- 離線任務的處理
- php的運行環境
MySQL集群化管理
因為云存儲沒有提供關系數據的存儲功能,為了降低用戶的開發門檻,我們需要一個MYSQL的集群化來完成類似的功能。MYSQL的集群化,主要是完成MYSQL讀寫分離和主從同步功能。
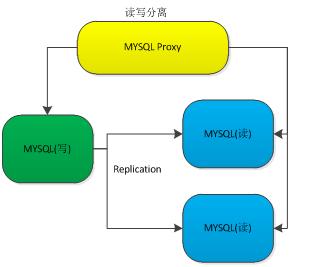
通過這種架構,保證了開發者不需要關心MYSQL的數據故障等問題。因為MYSQL Proxy會自動的進行主從切換和讀寫分離。這里我們要開發的就是解析SQL語句,完成相關的用戶認證,并完成相關的后臺轉發、接收。
MYSQL的集群化管理沒有解決分布式的問題,這個地方我們認為不需要解決。因為互聯網在線業務類的關系數據不會太大,大的數據都放到云存儲里面了,數據庫只存索引。還有,數據庫的分庫分表也相對成熟,索引數據也很難快速膨脹。如果用戶有對分布式索引的需求,可以考慮前面我們談到的有序表。
離線任務處理
離線任務處理主要解決,用戶需要做大量的cpu密集型的工作,包括圖片轉化,視頻轉化等。我們這里采用了一套消息隊列的方式進行離線處理。用戶將處理請求扔給消息隊列,執行機獲取消息隊列的消息之后,會執行相關的的用戶代碼。
php運行環境
php運行環境,主要解決php的分布式化問題。云平臺上跑的服務,千奇百怪,可能因為沒有流量,只用到實際機器的千分之一,也可能擁有巨額流量,需要上百臺機器支持。當然大部分服務沒有什么流量。對于傳統的虛擬化來說,1臺機器能虛擬化成32臺,已經慢的不行。這樣,一臺物理機只能部署32個app運用,對于基礎架構來說是不可接受的。因為互聯網上的云端運用,會急劇膨脹,所以我們需要一種新的虛擬化架構,能將機器的粒度切的更細。
這里我們使用php為開發語言展示一個輕量級的虛擬化技術。我們通過輕量級虛擬化技術,為每個用戶分配一組FAST CGI進程資源,通過Web端的調度,將請求引到各自的FAST CGI進程組中處理。這樣一臺機器能啟動多少個進程,我們就能虛擬化多少份。
如果網站流量很大,單機處理不了,該如何解決?我們是通過FAST CGI進程個數來調度的,單機資源不夠的情況下,我們會在多臺機器上分配進程,組成一個FAST CGI組,然后通知Web端,這個網站的請求可以分流到哪些FAST CGI中去。我們會有一個總控的Master來觀察各臺機器的負載,從而判斷是否要遷移FAST CGI進程。FAST CGI進程的遷移是簡單的,這臺機器KILL,在另外一臺機器重啟即可。
這個是我們php執行環境的架構。
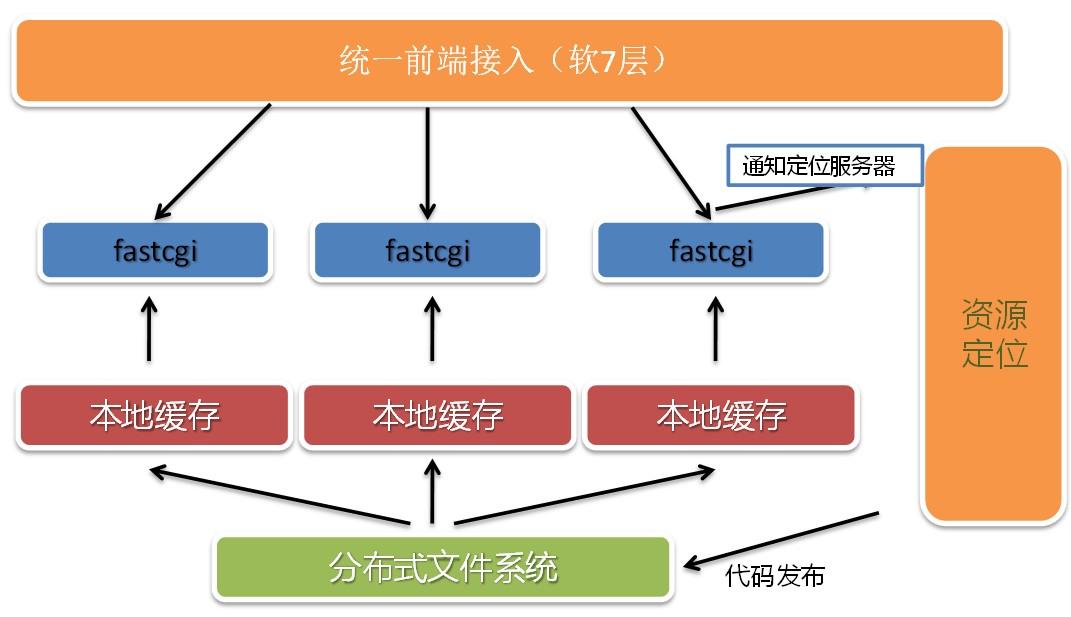
架構依賴于資源定位服務。資源定位通知前端接入,哪些機器負載還行,可以引流,哪些已經故障,或者壓力過大,不能引流。當A.baidu.com的流量過來的時候,前端接入會解析域名,并且根據資源定位獲取的數據(本地有緩存),分發到對應的某臺機器的FAST CGI端口上,執行php代碼后返回。因為FAST CGI讀取的用戶代碼存儲在網絡文件系統中,所以前端接入無論選擇哪臺FAST CGI都能夠有效的做處理。在實際過程中,我們發現網絡文件系統對性能,尤其是HTML的訪問性能影響很大,因此我們對每臺機器做了單機緩存。不過Cache失效是個非常難解決的問題,我們這里采用的方法是一但文件發生修改,資源定位會通知所有客戶機的該文件緩存失效,而且更新必須走同一的入口。由于我們只存儲代碼,效果還可以。有了分布式的網絡文件系統,用戶代碼更新也變得異常簡單。只要更新完成,通知緩存失效即可。
另外一個問題,如果運行平臺跑大量的垃圾網站,比如很多一天只有少量請求的網站。用輕量級虛擬化,即使1臺機器切出2000千份資源,還是很浪費的。對于這種運用,我們采用了FAST CGI復用,即很多小網站的請求都落到1個FAST CGI上,然后FAST CGI根據目前處理的網站,來獲取相關的配額控制。真正做到資源消耗跟訪問量成正比,沒訪問沒成本。這里可能用CGI更好點,不過為了架構統一下,這點優化不算麻煩。
小結
簡單介紹了App Engine所具有的能力,一個php的輕量級虛擬化,能夠將1臺機器虛擬成萬分之一,也能將萬臺機器合成1個大的虛擬環境。實現從萬分之一到萬倍計算資源的漸進分配。它成功解決了一個網站,從小到大的計算能力的無限擴展問題。
也介紹了云存儲所具備的能力,它支持海量的數據存儲,成功解決了一個網站,從小到大的存儲能力無限擴展問題。
整個云端運用,就是基于強悍可伸縮的計算能力和存儲能力之下構建的網站。我們真正做的就是邏輯開發,和各個終端下的特殊展現形式。用這套架構,實現一個視頻分享網站,電子書閱讀網站是容易的。減少了云端應用的開發門檻,整個云端產品也將豐富多彩。它們都用統一的架構,計算和存儲分離,程序開發無狀態化,持久性存儲放在云存儲中。
有給力的基礎架構,云端運用隨手拈來。目前在百度公司內部,這種架構已經有成型的運用,它極大的提高了應用服務的開發效率,降低服務運維成本和開發人員的技術門檻。百度內部云平臺遷移了大量的在線服務,有關百度的最新進展和數據,大家可以參考《QCon北京2011全球企業開發大會》公布的一些關于BAE的資料。
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播更多信息之目的,如作者信息標記有誤,請第一時間聯系我們修改或刪除,多謝。



