|
|
一、引言
對數(shù)據(jù)庫索引的關(guān)注從未淡出我的們的討論,那么數(shù)據(jù)庫索引是什么樣的?聚集索引與非聚集索引有什么不同?希望本文對各位同仁有一定的幫助。有不少存疑的地方,誠心希望各位不吝賜教指正,共同進步。[最近首頁之爭沸沸揚揚,也不知道這個放在這合適么,苦勞?功勞?……]
二、B-Tree
我們常見的數(shù)據(jù)庫系統(tǒng),其索引使用的數(shù)據(jù)結(jié)構(gòu)多是B-Tree或者B+Tree。例如,MsSql使用的是B+Tree,Oracle及Sysbase使用的是B-Tree。所以在最開始,簡單地介紹一下B-Tree。
B-Tree不同于Binary Tree(二叉樹,最多有兩個子樹),一棵M階的B-Tree滿足以下條件:
1)每個結(jié)點至多有M個孩子;
2)除根結(jié)點和葉結(jié)點外,其它每個結(jié)點至少有M/2個孩子;
3)根結(jié)點至少有兩個孩子(除非該樹僅包含一個結(jié)點);
4)所有葉結(jié)點在同一層,葉結(jié)點不包含任何關(guān)鍵字信息;
5)有K個關(guān)鍵字的非葉結(jié)點恰好包含K+1個孩子;
另外,對于一個結(jié)點,其內(nèi)部的關(guān)鍵字是從小到大排序的。以下是B-Tree(M=4)的樣例:
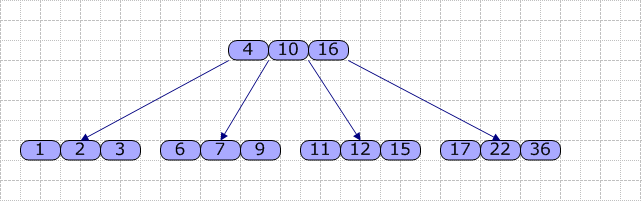
對于每個結(jié)點,主要包含一個關(guān)鍵字數(shù)組Key[],一個指針數(shù)組(指向兒子)Son[]。在B-Tree內(nèi),查找的流程是:使用順序查找(數(shù)組長度較短時)或折半查找方法查找Key[]數(shù)組,若找到關(guān)鍵字K,則返回該結(jié)點的地址及K在Key[]中的位置;否則,可確定K在某個Key[i]和Key[i+1]之間,則從Son[i]所指的子結(jié)點繼續(xù)查找,直到在某結(jié)點中查找成功;或直至找到葉結(jié)點且葉結(jié)點中的查找仍不成功時,查找過程失敗。
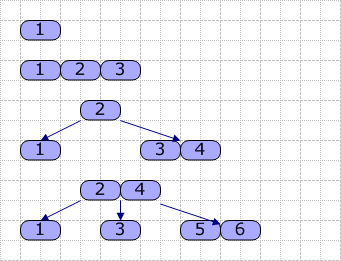
接著,我們使用以下圖片演示如何生成B-Tree(M=4,依次插入1~6):
從圖可見,當我們插入關(guān)鍵字4時,由于原結(jié)點已經(jīng)滿了,故進行分裂,基本按一半的原則進行分裂,然后取出中間的關(guān)鍵字2,升級(這里是成為根結(jié)點)。其它的依類推,就是這樣一個大概的過程。
三、數(shù)據(jù)庫索引
1.什么是索引
在數(shù)據(jù)庫中,索引的含義與日常意義上的“索引”一詞并無多大區(qū)別(想想小時候查字典),它是用于提高數(shù)據(jù)庫表數(shù)據(jù)訪問速度的數(shù)據(jù)庫對象。
A)索引可以避免全表掃描。多數(shù)查詢可以僅掃描少量索引頁及數(shù)據(jù)頁,而不是遍歷所有數(shù)據(jù)頁。
B)對于非聚集索引,有些查詢甚至可以不訪問數(shù)據(jù)頁。
C)聚集索引可以避免數(shù)據(jù)插入操作集中于表的最后一個數(shù)據(jù)頁。
D)一些情況下,索引還可用于避免排序操作。
當然,眾所周知,雖然索引可以提高查詢速度,但是它們也會導(dǎo)致數(shù)據(jù)庫系統(tǒng)更新數(shù)據(jù)的性能下降,因為大部分數(shù)據(jù)更新需要同時更新索引。
2.索引的存儲
一條索引記錄中包含的基本信息包括:鍵值(即你定義索引時指定的所有字段的值)+邏輯指針(指向數(shù)據(jù)頁或者另一索引頁)。
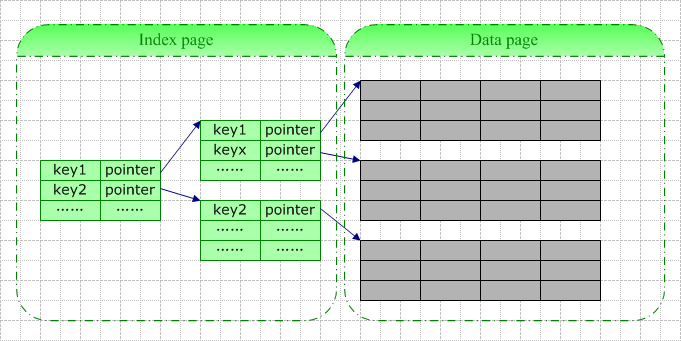
當你為一張空表創(chuàng)建索引時,數(shù)據(jù)庫系統(tǒng)將為你分配一個索引頁,該索引頁在你插入數(shù)據(jù)前一直是空的。此頁此時既是根結(jié)點,也是葉結(jié)點。每當你往表中插入一行數(shù)據(jù),數(shù)據(jù)庫系統(tǒng)即向此根結(jié)點中插入一行索引記錄。當根結(jié)點滿時,數(shù)據(jù)庫系統(tǒng)大抵按以下步驟進行分裂:
A)創(chuàng)建兩個兒子結(jié)點
B)將原根結(jié)點中的數(shù)據(jù)近似地拆成兩半,分別寫入新的兩個兒子結(jié)點
C)根結(jié)點中加上指向兩個兒子結(jié)點的指針
通常狀況下,由于索引記錄僅包含索引字段值(以及4-9字節(jié)的指針),索引實體比真實的數(shù)據(jù)行要小許多,索引頁相較數(shù)據(jù)頁來說要密集許多。一個索引頁可以存儲數(shù)量更多的索引記錄,這意味著在索引中查找時在I/O上占很大的優(yōu)勢,理解這一點有助于從本質(zhì)上了解使用索引的優(yōu)勢。
3.索引的類型
A)聚集索引,表數(shù)據(jù)按照索引的順序來存儲的。對于聚集索引,葉子結(jié)點即存儲了真實的數(shù)據(jù)行,不再有另外單獨的數(shù)據(jù)頁。
B)非聚集索引,表數(shù)據(jù)存儲順序與索引順序無關(guān)。對于非聚集索引,葉結(jié)點包含索引字段值及指向數(shù)據(jù)頁數(shù)據(jù)行的邏輯指針,該層緊鄰數(shù)據(jù)頁,其行數(shù)量與數(shù)據(jù)表行數(shù)據(jù)量一致。
在一張表上只能創(chuàng)建一個聚集索引,因為真實數(shù)據(jù)的物理順序只可能是一種。如果一張表沒有聚集索引,那么它被稱為“堆集”(Heap)。這樣的表中的數(shù)據(jù)行沒有特定的順序,所有的新行將被添加的表的末尾位置。
4.聚集索引
在聚集索引中,葉結(jié)點也即數(shù)據(jù)結(jié)點,所有數(shù)據(jù)行的存儲順序與索引的存儲順序一致。
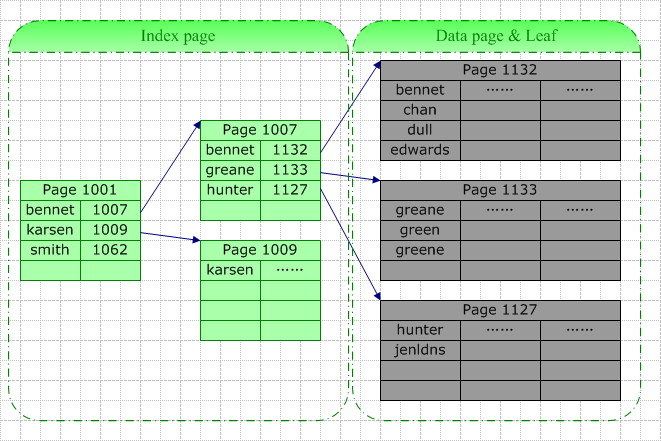
1)聚集索引與查詢操作
如上圖,我們在名字字段上建立聚集索引,當需要在根據(jù)此字段查找特定的記錄時,數(shù)據(jù)庫系統(tǒng)會根據(jù)特定的系統(tǒng)表查找的此索引的根,然后根據(jù)指針查找下一個,直到找到。例如我們要查詢“Green”,由于它介于[BenNET,Karsen],據(jù)此我們找到了索引頁1007,在該頁中“Green”介于[Greane, Hunter]間,據(jù)此我們找到葉結(jié)點1133(也即數(shù)據(jù)結(jié)點),并最終在此頁中找以了目標數(shù)據(jù)行。
此次查詢的IO包括3個索引頁的查詢(其中最后一次實際上是在數(shù)據(jù)頁中查詢)。這里的查找可能是從磁盤讀取(Physical Read)或是從緩存中讀取(Logical Read),如果此表訪問頻率較高,那么索引樹中較高層的索引很可能在緩存中被找到。所以真正的IO可能小于上面的情況。
2)聚集索引與插入操作
最簡單的情況下,插入操作根據(jù)索引找到對應(yīng)的數(shù)據(jù)頁,然后通過挪動已有的記錄為新數(shù)據(jù)騰出空間,最后插入數(shù)據(jù)。
如果數(shù)據(jù)頁已滿,則需要拆分數(shù)據(jù)頁(頁拆分是一種耗費資源的操作,一般數(shù)據(jù)庫系統(tǒng)中會有相應(yīng)的機制要盡量減少頁拆分的次數(shù),通常是通過為每頁預(yù)留空間來實現(xiàn)):
A)在該使用的數(shù)據(jù)段(extent)上分配新的數(shù)據(jù)頁,如果數(shù)據(jù)段已滿,則需要分配新段。
B)調(diào)整索引指針,這需要將相應(yīng)的索引頁讀入內(nèi)存并加鎖。
C)大約有一半的數(shù)據(jù)行被歸入新的數(shù)據(jù)頁中。
D)如果表還有非聚集索引,則需要更新這些索引指向新的數(shù)據(jù)頁。
特殊情況:
A)如果新插入的一條記錄包含很大的數(shù)據(jù),可能會分配兩個新數(shù)據(jù)頁,其中之一用來存儲新記錄,另一存儲從原頁中拆分出來的數(shù)據(jù)。
B)通常數(shù)據(jù)庫系統(tǒng)中會將重復(fù)的數(shù)據(jù)記錄存儲于相同的頁中。
C)類似于自增列為聚集索引的,數(shù)據(jù)庫系統(tǒng)可能并不拆分數(shù)據(jù)頁,頁只是簡單的新添數(shù)據(jù)頁。
3)聚集索引與刪除操作
刪除行將導(dǎo)致其下方的數(shù)據(jù)行向上移動以填充刪除記錄造成的空白。
如果刪除的行是該數(shù)據(jù)頁中的最后一行,那么該數(shù)據(jù)頁將被回收,相應(yīng)的索引頁中的記錄將被刪除。如果回收的數(shù)據(jù)頁位于跟該表的其它數(shù)據(jù)頁相同的段上,那么它可能在隨后的時間內(nèi)被利用。如果該數(shù)據(jù)頁是該段的唯一一個數(shù)據(jù)頁,則該段也被回收。
對于數(shù)據(jù)的刪除操作,可能導(dǎo)致索引頁中僅有一條記錄,這時,該記錄可能會被移至鄰近的索引頁中,原索引頁將被回收,即所謂的“索引合并”。
5.非聚集索引
非聚集索引與聚集索引相比:
A)葉子結(jié)點并非數(shù)據(jù)結(jié)點
B)葉子結(jié)點為每一真正的數(shù)據(jù)行存儲一個“鍵-指針”對
C)葉子結(jié)點中還存儲了一個指針偏移量,根據(jù)頁指針及指針偏移量可以定位到具體的數(shù)據(jù)行。
D)類似的,在除葉結(jié)點外的其它索引結(jié)點,存儲的也是類似的內(nèi)容,只不過它是指向下一級的索引頁的。
聚集索引是一種稀疏索引,數(shù)據(jù)頁上一級的索引頁存儲的是頁指針,而不是行指針。而對于非聚集索引,則是密集索引,在數(shù)據(jù)頁的上一級索引頁它為每一個數(shù)據(jù)行存儲一條索引記錄。
對于根與中間級的索引記錄,它的結(jié)構(gòu)包括:
A)索引字段值
B)RowId(即對應(yīng)數(shù)據(jù)頁的頁指針+指針偏移量)。在高層的索引頁中包含RowId是為了當索引允許重復(fù)值時,當更改數(shù)據(jù)時精確定位數(shù)據(jù)行。
C)下一級索引頁的指針
對于葉子層的索引對象,它的結(jié)構(gòu)包括:
A)索引字段值
B)RowId
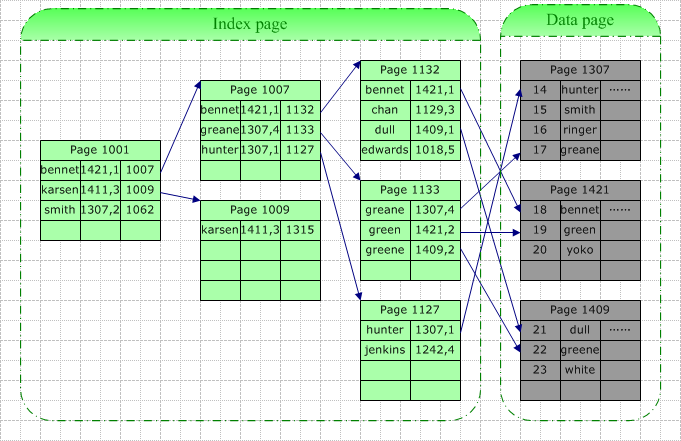
1)非聚集索引與查詢操作
針對上圖,如果我們同樣查找“Green”,那么一次查詢操作將包含以下IO:3個索引頁的讀取+1個數(shù)據(jù)頁的讀取。同樣,由于緩存的關(guān)系,真實的IO實際可能要小于上面列出的。
2)非聚集索引與插入操作
如果一張表包含一個非聚集索引但沒有聚集索引,則新的數(shù)據(jù)將被插入到最末一個數(shù)據(jù)頁中,然后非聚集索引將被更新。如果也包含聚集索引,該聚集索引將被用于查找新行將要處于什么位置,隨后,聚集索引、以及非聚集索引將被更新。
3)非聚集索引與刪除操作
如果在刪除命令的Where子句中包含的列上,建有非聚集索引,那么該非聚集索引將被用于查找數(shù)據(jù)行的位置,數(shù)據(jù)刪除之后,位于索引葉子上的對應(yīng)記錄也將被刪除。如果該表上有其它非聚集索引,則它們?nèi)~子結(jié)點上的相應(yīng)數(shù)據(jù)也要刪除。
如果刪除的數(shù)據(jù)是該數(shù)所頁中的唯一一條,則該頁也被回收,同時需要更新各個索引樹上的指針。
由于沒有自動的合并功能,如果應(yīng)用程序中有頻繁的隨機刪除操作,最后可能導(dǎo)致表包含多個數(shù)據(jù)頁,但每個頁中只有少量數(shù)據(jù)。
6.索引覆蓋
索引覆蓋是這樣一種索引策略:當某一查詢中包含的所需字段皆包含于一個索引中,此時索引將大大提高查詢性能。
包含多個字段的索引,稱為復(fù)合索引。索引最多可以包含31個字段,索引記錄最大長度為600B。如果你在若干個字段上創(chuàng)建了一個復(fù)合的非聚集索引,且你的查詢中所需Select字段及Where,Order By,Group By,Having子句中所涉及的字段都包含在索引中,則只搜索索引頁即可滿足查詢,而不需要訪問數(shù)據(jù)頁。由于非聚集索引的葉結(jié)點包含所有數(shù)據(jù)行中的索引列值,使用這些結(jié)點即可返回真正的數(shù)據(jù),這種情況稱之為“索引覆蓋”。
在索引覆蓋的情況下,包含兩種索引掃描:
A)匹配索引掃描
B)非匹配索引掃描
1)匹配索引掃描
此類索引掃描可以讓我們省去訪問數(shù)據(jù)頁的步驟,當查詢僅返回一行數(shù)據(jù)時,性能提高是有限的,但在范圍查詢的情況下,性能提高將隨結(jié)果集數(shù)量的增長而增長。
針對此類掃描,索引必須包含查詢中涉及的的所有字段,另外,還需要滿足:Where子句中包含索引中的“引導(dǎo)列”(Leading Column),例如一個復(fù)合索引包含A,B,C,D四列,則A為“引導(dǎo)列”。如果Where子句中所包含列是BCD或者BD等情況,則只能使用非匹配索引掃描。
2)非配置索引掃描
正如上述,如果Where子句中不包含索引的導(dǎo)引列,那么將使用非配置索引掃描。這最終導(dǎo)致掃描索引樹上的所有葉子結(jié)點,當然,它的性能通常仍強于掃描所有的數(shù)據(jù)頁。
[參考]
[1]http://manuals.sybase.com/onlinebooks/group-asarc/asg1200e/aseperf/@Generic__BookTextView/3358
[2] http://publib.boulder.ibm.com/infocenter/idshelp/v10/index.jsp?topic=/com.ibm.adref.doc/adref235.htm
it知識庫:漫談數(shù)據(jù)庫索引,轉(zhuǎn)載需保留來源!
鄭重聲明:本文版權(quán)歸原作者所有,轉(zhuǎn)載文章僅為傳播更多信息之目的,如作者信息標記有誤,請第一時間聯(lián)系我們修改或刪除,多謝。



