|
|
1. 數據庫的數據存儲
1.1文件:
我們一旦創建一個數據庫,都會生成兩個文件:
DataBaseName.mdf: 主文件,這是數據庫中的數據最終存放的地方。
DataBaseName.ldf:日志文件,由數據操作產生的一系列日志記錄。
1.2分區:
在一個給定的文件中,為表和索引分配空間的基本存儲單位。 1個區占64KB,由8個連續的頁組成。 如果一個分區已滿,但需存一條新的記錄,那么該記錄將占用整個新分區的空間。
1.3 頁:
分區中的一個分配單位。這是實際數據行最終存放的地方。 頁用于存儲數據行。
Sql Server有多種類型的頁:
Data, Index,BLOB,GAM(Global Allocation Map),SGAM,PFS(Page Free Space),IAM(Index Allocation Map),BCM(Bulk Changed Map)等。
2. 索引
2.1.1索引
索引是與表或視圖關聯的磁盤上結構,可以加快從表或視圖中檢索行的速度。索引包含由表或視圖中的一列或多列生成的鍵。這些鍵存儲在一個結構(B 樹)中,使 SQL Server 可以快速有效地查找與鍵值關聯的行。
通俗點說,索引與表或視圖相關,旨在加快檢索速度。索引本身占據存儲空間,通過索引,數據便會以B樹形式存儲。因此也加快了查詢速度。
2.1.2聚集索引
聚集索引根據數據行的鍵值在表或視圖中排序和存儲這些數據行。索引定義中包含聚集索引列。每個表只能有一個聚集索引,因為數據行本身只能按一個順序排序。只有當表包含聚集索引時,表中的數據行才按排序順序存儲。如果表具有聚集索引,則該表稱為聚集表。如果表沒有聚集索引,則其數據行存儲在一個稱為堆的無序結構中。
通俗點說,聚集索引的頁存儲的是實際數據。每個表只能建立唯一的聚集索引,但也可以沒有。
如果建立聚集索引,那么表中數據以B樹形式存儲數據。
對于聚集索引的理解,打個比方,即英文字典的單詞編排。 英文字典單詞以A,B,C,D….X,Y,Z的形式順序編排,如果我們查找 Good 單詞,我們首先定位到G,然后定位o – o-d. 最終查找到Good,便是good實際存在的地方。建聚集索引需要至少相當該表120%的附加空間,以存放該表的副本和索引中間頁。
2.1.3非聚集索引
非聚集索引具有獨立于數據行的結構。非聚集索引包含非聚集索引鍵值,并且每個鍵值項都有指向包含該鍵值的數據行的指針。
從非聚集索引中的索引行指向數據行的指針稱為行定位器。行定位器的結構取決于數據頁是存儲在堆中還是聚集表中。對于堆,行定位器是指向行的指針。對于聚集表,行定位器是聚集索引鍵。
通俗點說,非聚集索引的頁存儲的是不是實際數據,而是實際數據的地址。一個表可以存在多個非聚集索引。在Sql Server2005中,每個表最多可以建立249個,而在Sql server2008中,則最多可以建立999個非聚集索引。
對于非聚集索引的理解,即新華字典的“偏旁部首”查字法。遇到您不認識的字,不知道它的發音,這時候,您就不能按照剛才的方法找到您要查的字,而需要去根據“偏旁部首”查到您要找的字,然后根據這個字后的頁碼直接翻到某頁來找到您要找的字。
但您結合“部首目錄”和“檢字表”而查到的字的排序并不是真正的正文的排序方法,比如您查“張”字,我們可以看到在查部首之后的檢字表中“張”的頁碼是672頁,檢字表中“張”的上面是“馳”字,但頁碼卻是63頁,“張”的下面是“弩”字,頁面是390頁。很顯然,這些字并不是真正的分別位于“張”字的上下方,現在您看到的連續的“馳、張、弩”三字實際上就是他們在非聚集索引中的排序,是字典正文中的字在非聚集索引中的映射。我們可以通過這種方式來找到您所需要的字,但它需要兩個過程,先找到目錄中的結果,然后再翻到您所需要的頁碼。我們把這種目錄純粹是目錄,正文純粹是正文的排序方式稱為“非聚集索引”。
2.1.4 覆蓋索引:
覆蓋索引是指那些索引項中包含查尋所需要的全部信息的非聚集索引,這種索引之所以比較快也正是因為索引頁中包含了查尋所必須的數據,不需去訪問數據頁。 如果非聚簇索引中包含結果數據,那么它的查詢速度將快于聚集索引。
但是由于覆蓋索引的索引項比較多,要占用比較大的空間。而且update 操作會引起索引值改變。所以如果潛在的覆蓋查詢并不常用或不太關鍵,則覆蓋索引的增加反而會降低性能。
2.1.5 主鍵和索引
主鍵:表通常具有包含唯一標識表中每一行的值的一列或一組列。這樣的一列或多列稱為表的主鍵 (PK),用于強制表的實體完整性。在創建或修改表時,您可以通過定義 PRIMARY KEY 約束來創建主鍵。 它是一種唯一索引。
下面是一個簡單的比較表
| 主鍵 | 聚集索引 |
用途 | 強制表的實體完整性 | 對數據行的排序,方便查詢用 |
一個表多少個 | 一個表最多一個主鍵 | 一個表最多一個聚集索引 |
是否允許多個字段來定義 | 一個主鍵可以多個字段來定義 | 一個索引可以多個字段來定義 |
|
|
|
是否允許 null 數據行出現 | 如果要創建的數據列中數據存在null,無法建立主鍵。 | 沒有限制建立聚集索引的列一定必須 not null . |
是否要求數據必須唯一 | 要求數據必須唯一 | 數據即可以唯一,也可以不唯一。看你定義這個索引的 UNIQUE 設置。 |
|
|
|
創建的邏輯 | 數據庫在創建主鍵同時,會自動建立一個唯一索引。 | 如果未使用 UNIQUE 屬性創建聚集索引,數據庫引擎 將向表自動添加一個四字節 uniqueifier 列。 |
2.2 索引的存儲結構
2.1.1 整表掃描和索引掃描
整表掃描和索引掃描是Sql Server數據庫檢索到數據的唯一的兩種方式。除此之外,沒有第三種方式供Sql Server檢索到數據。
整表掃描
最直接的檢索方式, Sql Server進行表掃描時,會從表頭開始掃描,直到整個表結束。 當找到符合條件的記錄,便把該記錄存在結果集中。對于小數據量的表,這是一種很快捷的方式。如果沒有為表創建索引,那么Sql server便按這種方式檢索數據。
索引掃描
如果為表創建了索引,在進行檢索前,Sql Server優化器會根據查詢條件,從可用的索引中選擇最優化的索引。檢索時,便會遍歷B樹,當找到符合條件的記錄,便把該記錄存在結果集中。因此,檢索大數據量的表,使用索引相對于整表掃描會顯著地提高性能。
2.1.2 B-Tree 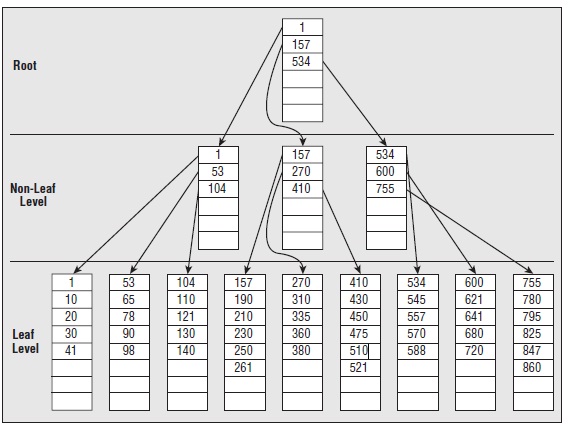
2.2.3 聚集索引
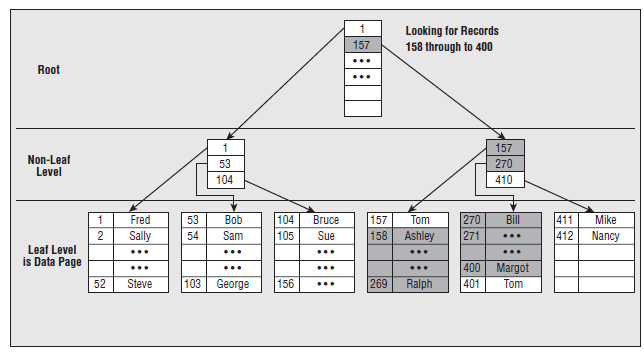
葉子節點存放的是實際的數據。索引的入口點存放在master->sys.indexes中。
2.2.4 非聚集索引
2.4.1 堆上的非聚集索引(Non-clustered index on heap)
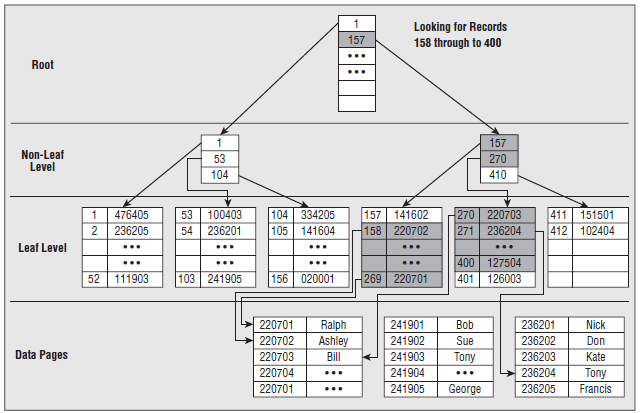
與聚集索引很類似。不同處在:葉子節點存放的不是實際數據,而是指向實際數據的指針。檢索速度非常接近于聚集索引,比起聚集索引,實際上只是多一步由根據指針檢索到實際數據的過程。
2.4.2 聚集表上的非聚集索引
3. 管理索引
3.1 創建 it知識庫:數據庫索引,你該了解的幾件事,轉載需保留來源! 鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播更多信息之目的,如作者信息標記有誤,請第一時間聯系我們修改或刪除,多謝。CREATE [UNIQUE] [CLUSTERED|NONCLUSTERED]
INDEX <index name> ON <table or view name>
(<column name> [ASC|DESC] [,...n])
INCLUDE (<column name> [, ...n])
[WITH
[PAD_INDEX = { ON | OFF }]
[[,] FILLFACTOR = <fillfactor>]
[[,] IGNORE_DUP_KEY = { ON | OFF }]
[[,] DROP_EXISTING = { ON | OFF }]
[[,] STATISTICS_NORECOMPUTE = { ON | OFF }]
[[,] SORT_IN_TEMPDB = { ON | OFF }]
[[,] ONLINE = { ON | OFF }
[[,] ALLOW_ROW_LOCKS = { ON | OFF }
[[,] ALLOW_PAGE_LOCKS = { ON | OFF }
[[,] MAXDOP = <maximum degree of parallelism>
]
[ON {<filegroup> | <partition scheme name> | DEFAULT }]



