|
|
分區(qū)請(qǐng)三思:
1、雖然分區(qū)可以帶來眾多的好處,但是同時(shí)也增加了實(shí)現(xiàn)對(duì)象的管理費(fèi)用和復(fù)雜性。因此在進(jìn)行分區(qū)之前要首先仔細(xì)的考慮以確定是否應(yīng)為對(duì)象進(jìn)行分區(qū)。
2、在確定了為對(duì)象進(jìn)行分區(qū)后,下一步就要確定分區(qū)鍵和分區(qū)數(shù)。要確定分區(qū)數(shù)據(jù),應(yīng)先評(píng)估您的數(shù)據(jù)中是否存在邏輯分組和模式。
3、確定是否應(yīng)使用多個(gè)文件分組。為了有助于優(yōu)化性能和維護(hù),應(yīng)使用文件組分離數(shù)據(jù)。文件組是數(shù)據(jù)庫數(shù)據(jù)文件的邏輯組合,它可以對(duì)數(shù)據(jù)文件進(jìn)行管理和分配,以便提高數(shù)據(jù)庫文件的并發(fā)訪問效率。
為了簡(jiǎn)化操作,SQL Server 2008中為表分區(qū)提供了相關(guān)的操作。
操作的順序:
1、先定義文件組
2、指定哪些輔助數(shù)據(jù)庫文件屬于這個(gè)文件組
3、將表放入到文件組中
數(shù)據(jù)庫分文件組(指定磁盤):
數(shù)據(jù)實(shí)際上是依附于表來存在的,我們將表放入到文件組中,而文件組是一個(gè)邏輯的概念,其實(shí)體是輔助數(shù)據(jù)庫文件(ndr),所以就等于將我們指定的數(shù)據(jù)放入到了指定的輔助數(shù)據(jù)庫文件中,然后如果將這些輔助數(shù)據(jù)庫文件放入在不同的磁盤分區(qū)中,就可以最終實(shí)現(xiàn)有針對(duì)性的對(duì)相應(yīng)的數(shù)據(jù)實(shí)現(xiàn)性能的優(yōu)化。
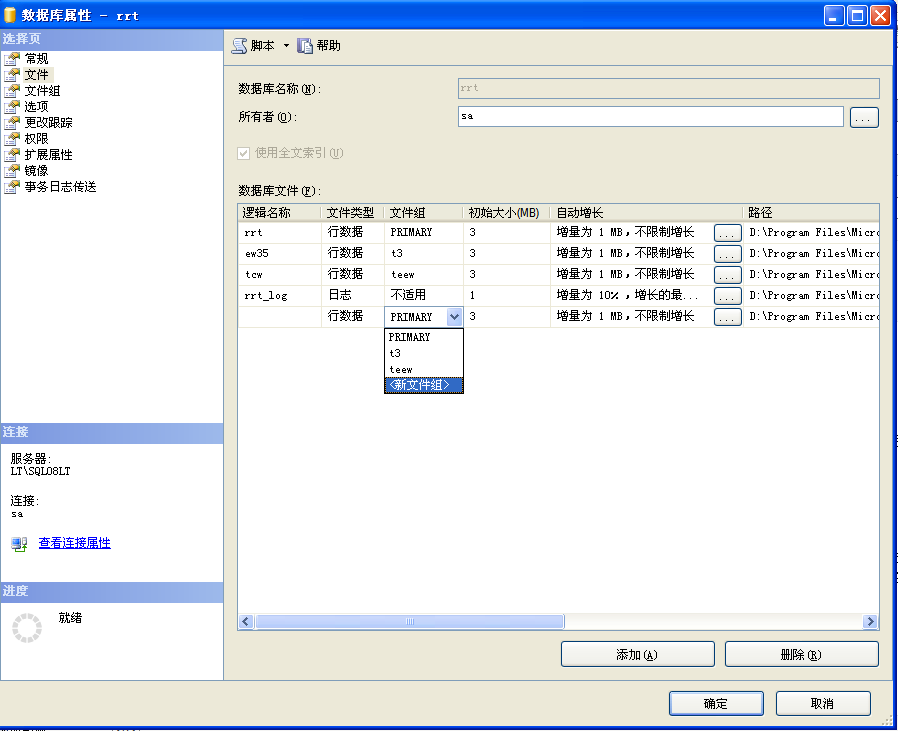
創(chuàng)建文件組時(shí),定義不同的文件組名稱,可以有序地進(jìn)行下一步表分區(qū)的分區(qū)映射文件組,如上圖(選擇數(shù)據(jù)庫,右鍵查看屬性圖)。
一個(gè)水平分區(qū)表中有多個(gè)分區(qū),每個(gè)分區(qū)對(duì)應(yīng)一個(gè)文件組,這樣就產(chǎn)生了很多文件組,因此性能也會(huì)有所提升,包括I/O性能提升,因?yàn)樗蟹謪^(qū)可以駐扎在一個(gè)不同的磁盤上。另一個(gè)好處是可以通過備份文件組單獨(dú)備份一個(gè)分區(qū)。此外,SQL Server數(shù)據(jù)庫引擎可以智能判斷哪個(gè)分區(qū)上存放了什么數(shù)據(jù),如果不止一個(gè)分區(qū)被訪問,那么還可以借助多處理器實(shí)現(xiàn)并行數(shù)據(jù)檢索。這種設(shè)計(jì)也充分利用了分區(qū)表的優(yōu)勢(shì)。
1、提高可伸縮性和可管理性:在SQL Server 2005中建立分區(qū),改善大型表以及具有各種訪問模式的表的可伸縮性和可管理性。
2、提高性能
3、只有將數(shù)據(jù)分區(qū)分到不同的磁盤上,才會(huì)有較大的提升。
4、因?yàn)樵谶\(yùn)行涉及表間聯(lián)接的查詢時(shí),多個(gè)磁頭可以同時(shí)讀取數(shù)據(jù)。
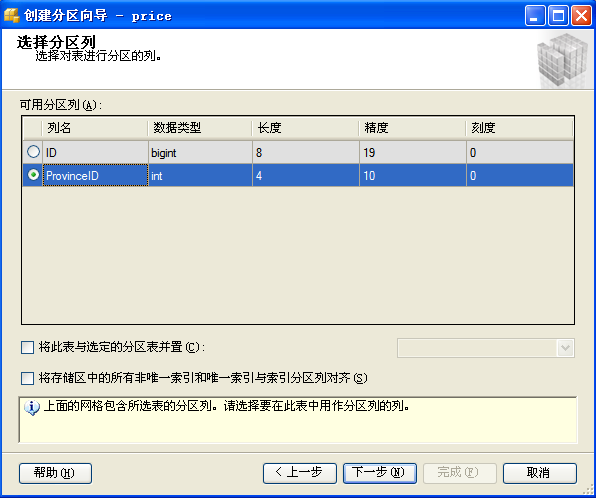
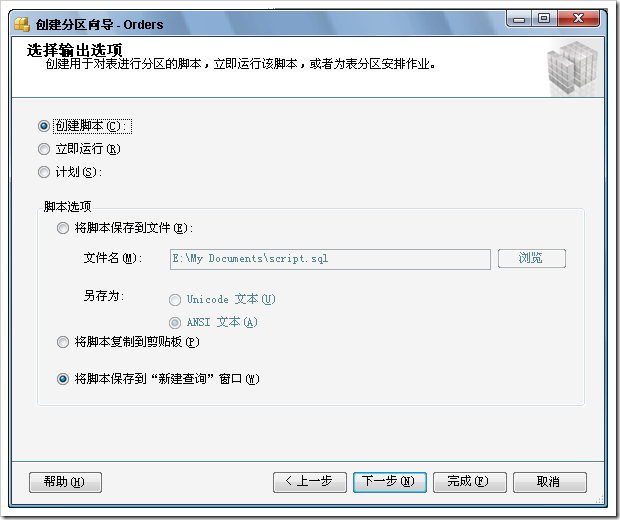
對(duì)SQL Server數(shù)據(jù)表進(jìn)行分區(qū)的過程分為三個(gè)步驟:
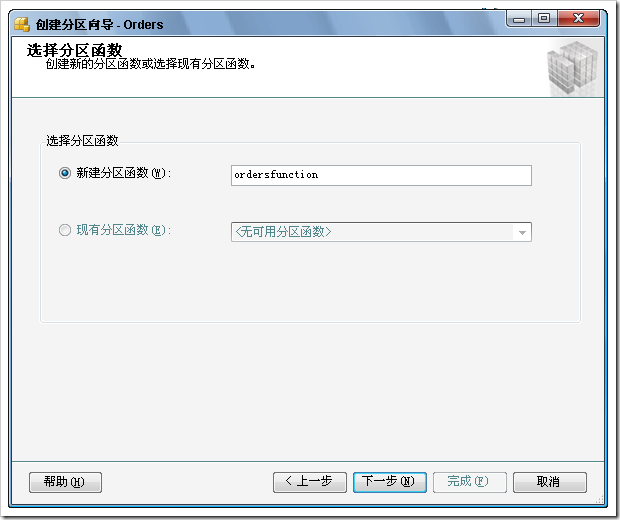
1) 建立分區(qū)函數(shù)
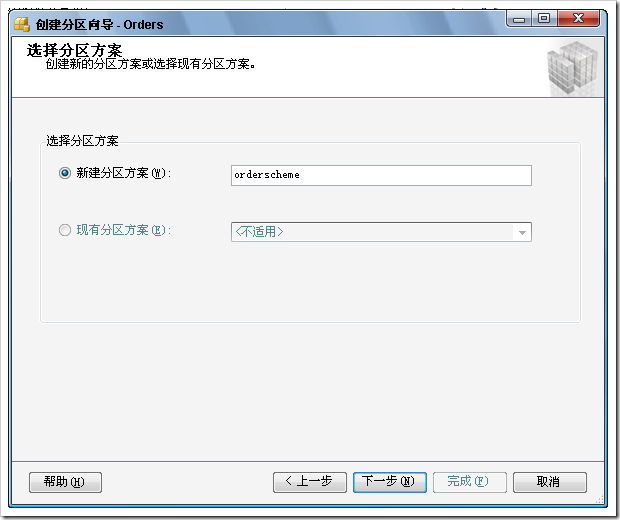
2) 建立分區(qū)方案
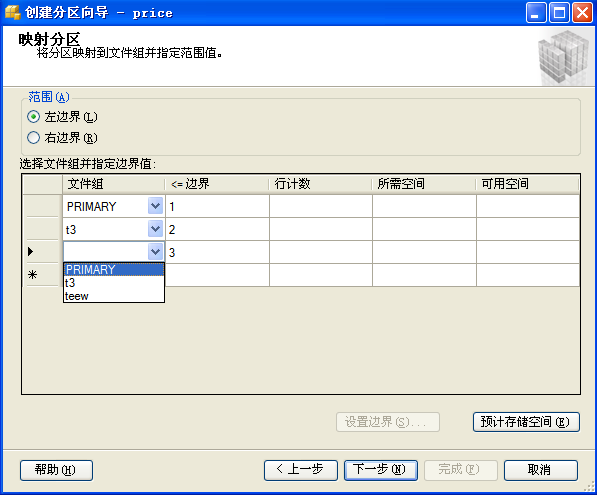
3) 對(duì)表格進(jìn)行分區(qū)
步驟如下:
it知識(shí)庫:SQL Server表分區(qū)詳解,轉(zhuǎn)載需保留來源!
鄭重聲明:本文版權(quán)歸原作者所有,轉(zhuǎn)載文章僅為傳播更多信息之目的,如作者信息標(biāo)記有誤,請(qǐng)第一時(shí)間聯(lián)系我們修改或刪除,多謝。



